the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Oct 2019
| 30 Oct 2019
Assessing the impacts of reservoirs on downstream flood frequency by coupling the effect of scheduling-related multivariate rainfall with an indicator of reservoir effects
Bin Xiong
Jun Xia
Chong-Yu Xu
Cong Jiang
Tao Du
Many studies have shown that downstream flood regimes have been significantly altered by upstream reservoir operation. Reservoir effects on the downstream flow regime are normally performed by comparing the pre-dam and post-dam frequencies of certain streamflow indicators, such as floods and droughts. In this study, a rainfall–reservoir composite index (RRCI) is developed to precisely quantify reservoir impacts on downstream flood frequency under a framework of a covariate-based nonstationary flood frequency analysis using the Bayesian inference method. The RRCI is derived from a combination of both a reservoir index (RI) for measuring the effects of reservoir storage capacity and a rainfall index. More precisely, the OR joint (the type of possible joint events based on the OR operator) exceedance probability (OR-JEP) of certain scheduling-related variables selected out of five variables that describe the multiday antecedent rainfall input (MARI) is used to measure the effects of antecedent rainfall on reservoir operation. Then, the RI-dependent or RRCI-dependent distribution parameters and five distributions, the gamma, Weibull, lognormal, Gumbel, and generalized extreme value, are used to analyze the annual maximum daily flow (AMDF) of the Ankang, Huangjiagang, and Huangzhuang gauging stations of the Han River, China. A phenomenon is observed in which although most of the floods that peak downstream of reservoirs have been reduced in magnitude by upstream reservoirs, some relatively large flood events have still occurred, such as at the Huangzhuang station in 1983. The results of nonstationary flood frequency analysis show that, in comparison to the RI, the RRCI that combines both the RI and the OR-JEP resulted in a much better explanation for such phenomena of flood occurrences downstream of reservoirs. A Bayesian inference of the 100-year return level of the AMDF shows that the optimal RRCI-dependent distribution, compared to the RI-dependent one, results in relatively smaller estimated values. However, exceptions exist due to some low OR-JEP values. In addition, it provides a smaller uncertainty range. This study highlights the necessity of including antecedent rainfall effects, in addition to the effects of reservoir storage capacity, on reservoir operation to assess the reservoir effects on downstream flood frequency. This analysis can provide a more comprehensive approach for downstream flood risk management under the impacts of reservoirs.
- Article
(4657 KB) -
Supplement
(591 KB) - BibTeX
- EndNote





River floods are generated by various complex nonlinear processes involving physical factors, including “hydrological pre-conditions (e.g., soil saturation, snow cover), meteorological conditions (e.g., amount, intensity, and the spatial and temporal distribution of rainfall), runoff generation processes, and river routing (e.g., superposition of flood waves in the main river and its tributaries)” (Wyżga et al., 2016). In general, without reservoirs, the downstream flood extremes of most rain-dominated basins are primarily related to extreme rainfall events in the drainage area. However, with reservoirs, the downstream flood regimes should be totally different due to upstream flood control scheduling. In the literature, the significant hydrological alterations caused by reservoirs have been demonstrated in the many areas of the world. Graf (1999) showed that dams have more significant effects on streamflow in America than global climate change. Benito and Thorndycraft (2005) reported various significant changes across the United States in pre-dam and post-dam hydrologic regimes (e.g., minimum and maximum flows over different durations). Batalla et al. (2004) demonstrated an evident reservoir-induced hydrologic alteration in northeastern Spain. Yang et al. (2008) demonstrated the spatial variability in hydrological regimes alterations caused by the reservoirs in the middle and lower Yellow River in China. Mei et al. (2015) found that the Three Gorges Dam, the largest dam in the world, has significantly changed downstream hydrological regimes. In recent years, the cause–effect mechanisms of downstream flood peak reductions were also investigated by some researchers (Ayalew et al., 2013, 2015; Volpi et al., 2018). For example, Volpi et al. (2018) suggested that for a single reservoir, the downstream flood peak reduction was primarily dependent on its position along the river, its spillway, and its storage capacity based on a parsimonious instantaneous unit-hydrograph-based model. These studies have revealed that it is crucial to assess the impacts of reservoirs on downstream flood regimes for the success of downstream flood risk management.
Flood frequency analysis is the most common technique used by hydrologists to gain knowledge of flood regimes. In conventional or stationary frequency analyses, a basic hypothesis is that hydrologic time series maintains stationarity; i.e., it is “free of trends, shifts, or periodicity (cyclicity)” (Salas, 1993). However, in many cases, observations of changes in flood regimes have demonstrated that this strict assumption is invalid (Kwon et al., 2008; Milly et al., 2008). Nonstationarity in downstream flood regimes of dams makes frequency analyses more complicated. Actually, the frequency of downstream floods of dams is closely related to upstream flood operations. In recent years, there have been many attempts to link flood-generating mechanisms and reservoir operations to the frequency of downstream floods (Gilroy and Mccuen, 2012; Goel et al., 1997; Lee et al., 2017; Liang et al., 2018; Su and Chen, 2019; Yan et al., 2017).
Previous studies have meaningfully increased the knowledge about reservoir-induced nonstationarity of downstream hydrological extreme frequencies (Ayalew et al., 2013; López and Francés, 2013; Liang et al., 2018; Magilligan and Nislow, 2005; Su and Chen, 2019; Wang et al., 2017; Zhang et al., 2015). There are two main approaches to incorporate reservoir effects into flood frequency analyses: the hydrological model simulation approach and the nonstationary frequency modeling approach. In the first approach, the regulated flood time series can be simulated using three model components: the stochastic rainfall generator, the rainfall-runoff model, and the reservoir flood operation module, which includes the reservoir storage capacity, the size of release structures, and the operation rules. The continuous simulation method can explicitly account for the reservoir effects on floods in the hypothetical case. However, it is difficult to apply this approach to a majority of real cases (Volpi et al., 2018) because the simplifying assumptions of this approach are only satisfied in a few of basins with single small reservoirs. Furthermore, even if the basins meet the simplifying assumptions, the detailed information required in this approach is likely unavailable. Thus, our attention is focused on the second method, the nonstationary frequency modeling approach. Nonstationary distribution models have been widely used to deal with the nonstationarity of extreme value series. In nonstationary distribution models, the distribution parameters are expressed as the functions of covariates to determine the conditional distributions of extreme value series. According to extreme value theory, the maximum series can generally be described using the generalized extreme value (GEV) distribution. Thus, previous studies (El Adlouni et al., 2007; Ouarda and El-Adlouni, 2011) have used the nonstationary generalized extreme value distribution to describe the nonstationary maximum series. Scarf (1992) modeled the changes in the location and scale parameters of the GEV over time using the power function relationship. Coles (2001) introduced several time-dependent structures (e.g., trend, quadratic, and change point) into the location, scale, and shape parameters of the GEV. El Adlouni et al. (2007) provided a general nonstationary GEV model with an improved parameter estimate method. In recent years, “generalized additive models for location, scale, and shape” (GAMLSSs) have been widely used in nonstationary hydrological frequency analyses (Du et al., 2015; Jiang et al., 2014; López and Francés, 2013; Rigby and Stasinopoulos, 2005; Villarini et al., 2009). The GAMLSS provides various candidate distributions for frequency analysis, such as Weibull, gamma, Gumbel, and lognormal distributions. However, the GEV has rarely been involved in the candidate distributions of GAMLSSs. In terms of a parameter estimation method for the nonstationary distribution model, the maximum likelihood (ML) method is the most common parameter estimate method. However, the ML method for a nonstationary distribution model can lead to very high quantile estimator variances when using numerical techniques to solve the likelihood function when using a small sample (El Adlouni et al., 2007). El Adlouni et al. (2007) developed the generalized maximum likelihood (GML) method and demonstrated that the GML method had better performance than the ML method in all their cases. Ouarda and El-Adlouni (2011) introduced the Bayesian nonstationary frequency analysis. The Bayesian inference can obtain multiple estimates, forming a posterior distribution of model parameters. Thus, the Bayesian method is able to conveniently describe the uncertainty of flood estimates associated with the uncertainty of model parameters.
In the nonstationary frequency modeling approach, a dimensionless reservoir index (RI) was proposed by López and Francés (2013) as an indicator of reservoir effects, and it generally is used as a covariate for the expression of the distribution parameters (e.g., location parameter; Jiang et al., 2014; López and Francés, 2013). Liang et al. (2018) modified the reservoir index by replacing the mean annual runoff in the expression of the RI with the annual runoff. Therefore, the modified reservoir index can reflect the impact of reservoirs on downstream flood extremes under various total inflow conditions each year. However, the precision and accuracy in the quantitative analysis of the reservoir effects on downstream floods need to be further improved. In fact, the effects of reservoirs may be closely related not only to the static reservoir storage capacity but also to the dynamic reservoir operations associated with multiple characteristics, such as the peak, the intensity, and the total volume of the multiday antecedent rainfall input (MARI) and not just annual runoff.
Therefore, the aim of the study is to develop an indicator, referred to as the rainfall–reservoir composite index (RRCI), that combines the effects of reservoir storage capacity and the MARI on reservoir operation. This indicator is then used as a covariate to assess the reservoir effects on the downstream flood frequency. The specific objectives of this study are (1) to develop the RRCI, (2) to compare the RRCI with the RI using a covariate-based nonstationary flood frequency analysis, and (3) to obtain the downstream flood estimation and its uncertainty based on the optimal nonstationary distribution using the Bayesian inference.
To quantify the effects of reservoirs on the frequency of the annual maximum daily flow (AMDF) series downstream of reservoirs, a three-step framework (Fig. 1), termed the covariate-based flood frequency analysis using the RRCI as a covariate, was established. In this section, the methods of this framework are introduced. First, a RI is defined by additionally considering the effects of reservoir sediment deposition on the storage capacity. Second, the RRCI is developed by combining the RI and a rainfall index. Next, the C-vine copula model is used to construct and calculate the rainfall index. Finally, the nonstationary distribution models that utilize the Bayesian estimation are explained.

Figure 1Flowchart of the nonstationary covariate-based flood frequency analysis using the rainfall–reservoir composite index (RRCI).
2.1 Reservoir index (RI)
Intuitively, the larger the reservoir capacity relative to the flow of a downstream gauging station, the greater the possible effects of the reservoir on the streamflow regime. To quantify reservoir-induced alterations to the downstream streamflow regime, Batalla et al. (2004) proposed an impounded runoff index (IRI), which is a ratio of reservoir capacity (RC) to (unimpaired) mean annual runoff () at the gauge station, denoted as . For a single reservoir, the IRI is a good indicator of the extent to which a reservoir alters streamflow. To analyze the effects of a multi-reservoir system on the downstream flood frequency, López and Francés (2013) proposed a dimensionless reservoir index. In this study, we additionally considered the effects of reservoir sediment deposition on the reservoir capacity. In accordance with López and Francés (2013), the RI for a downstream gauging station is defined as
where N is the total number of reservoirs upstream of the gauge station, Ai is the total basin area upstream of the ith reservoir, AT is the total basin area upstream of the gauge station, RCi is the total storage capacity of the ith reservoir, and LRi is the loss rate (%) of RCi due to the sediment deposition (Supplement). Equation (1) indicates that for a reservoir system consisting of small- and middle-sized reservoirs, the RI for the downstream gauging station is generally less than 1. However, for a system with some large reservoirs, such as multi-year regulating storage reservoirs, the RI of the downstream gauging station near this system may be close to 1 or higher.
2.2 Rainfall–reservoir composite index (RRCI)
In addition to the reservoir capacity, the MARI, which is an event of continuous multiday multivariate rainfall that forms the inflow event that will be regulated by the reservoir system to become the downstream extreme flow, is a key constraint for scheduling the reservoir system. In this study, to add the antecedent rainfall effects into the new indicator of reservoir effects, five variables were used to describe the MARI: the maximum M (the maximum daily rainfall in the MARI), the intensity I (the mean daily rainfall in the MARI), the volume V (the total daily rainfall in the MARI), the timing T (the end time of MARI during that year), and the distance L (the distance between the rainfall center and the outlet). The reason that M, I, V, and L were selected is because these variables will determine the peak, the total volume, and the peak appearance time of an inflow event. The variable T is utilized to capture information regarding the remaining storage capacity due to staged operation strategies during flood season used in some reservoirs. For the operation strategy that consists of increasing the flood limit water level in stages, it is expected that if the timing of the MARI is near the end of the flood season, the downstream AMDF will be less affected by reservoirs. This is because of the lesser remaining capacity during this period. The MARI variables that are selected to construct the new indicator are hereafter referred to as the scheduling-related MARI variables (denoted as ). The extraction procedure of the MARI is detailed in Sect. 3.2.
A new index is proposed in this study, the RRCI, to more comprehensively assess the effects of reservoirs on floods by incorporating the effects of the MARI. This index is defined as
where is the OR joint exceedance probability (OR-JEP), which is the probability that any one of the given set of values () for the scheduling-related MARI variables will be exceeded. Here, the OR-JEP acts as a rainfall index for measuring the MARI effects. The lower this probability, the greater effects the MARI has on reservoir operation. Then, it is expected that downstream floods could possibly obtain relatively large values and vice versa. Figure 2 illustrates the relationship in Eq. (2), which shows that the RRCI is conditional on both the OR-JEP and the RI. Equation (2) can then be expressed as
where F(⋅) is the cumulative distribution function (CDF) that determines the dependence relationship of the variables. The expectation of the RRCI is as follows:
In addition, for the OR case, the following is true:
Equations (3) and (5) indicate that, in addition to the RI, the RRCI is related to the number and the dependence relationship of the scheduling-related MARI variables. To obtain a reasonable RRCI, the unrelated MARI variables should not be incorporated. In this study, the number of MARI variables that were incorporated was no more than four to avoid a “dimension disaster” in modeling their dependence. To select the scheduling-related MARI variables, a three-step selection procedure was used that included the following: (1) selecting four variables from the five MARI variables by testing the significance of the Pearson correlation between the MARI variables and the AMDF, (2) calculating the RRCI for all possible subsets of the four variables using the d-dimensional ( copulas, then finally (3) identifying the variables by using the highest rank correlation coefficient between the RRCI and the AMDF. The construction method of the d-dimensional () distribution is described in the following subsection.

Figure 2Relationship in Eq. (2). (a) The contour plot of the RRCI against both the RI and the OR-JEP; panel (b) is the function curves of the RRCI against the OR-JEP under different values of RI.
2.3 C-vine Copula model
In this subsection, a C-vine Copula model for the construction of the continuous d-dimensional distribution is clarified. Sklar's theorem (Sklar, 1959) showed that for a continuous d-dimensional distribution, the one-dimensional marginals and dependence structure can be separated, and the dependence can be represented using a copula formula as follows:
where ui is the univariate marginal distribution of Xi, C(⋅) is the copula function, θc is the copula parameter vector, θi is the parameter vector of the ith marginal distribution, and is the parameter vector of the entire d-dimensional distribution. Thus, the construction of can be separated into two steps: the first is the modeling of the univariate marginals, and the second is the modeling of the dependence structure. For the first step, the empirical distribution is used as the univariate marginal distributions, and the change points of the variables are tested using the Pettitt test (Pettitt, 1979). Then, if there are any, the marginal distribution and the change point will be addressed using the estimation method (Xiong et al., 2015). Then, for the second step, the copula construction for the dependence modeling is based on the pair-copula construction method, which has been widely used in previous research (Aas et al., 2009; Xiong et al., 2015). According to Aas et al. (2009), the joint density function is written as
The d-dimensional copula density , which can be decomposed into bivariate copulas, corresponding to a C-vine structure, is given by
where is the density function of a bivariate pair copula, and is a parameter vector of the corresponding bivariate pair copula. Therefore, the marginal conditional distribution is
where is a bivariate copula distribution function. The maximum dimensionality covered in this study was four. Thus for a four-dimensional copula (of which the decomposition is shown in Fig. 3), the general expression of Eq. (8) is

Figure 3Decomposition of a C-vine copula using four variables and three trees (denoted by T1, T2, and T3).
2.4 Covariate-based nonstationary frequency analysis using the Bayesian estimation
The covariate-based extreme frequency analysis has been widely used (Villarini et al., 2009; Ouarda and El-Adlouni, 2011; López and Francés, 2013; Xiong et al., 2018). According to these studies, five distributions, namely the gamma (GA), Weibull (WEI), lognormal (LOGNO), Gumbel (GU), and the generalized extreme value (GEV) distribution, were used as candidate distributions in this study. In addition, their density functions, the corresponding moments, and the used link functions are shown in Table 1. In the following, the nonstationary distribution models based on Bayesian estimation are developed for a covariate-based flood frequency analysis.
Table 1Summary of the probability density functions, the corresponding moments, and the used link functions for nonstationary flood frequency analysis.

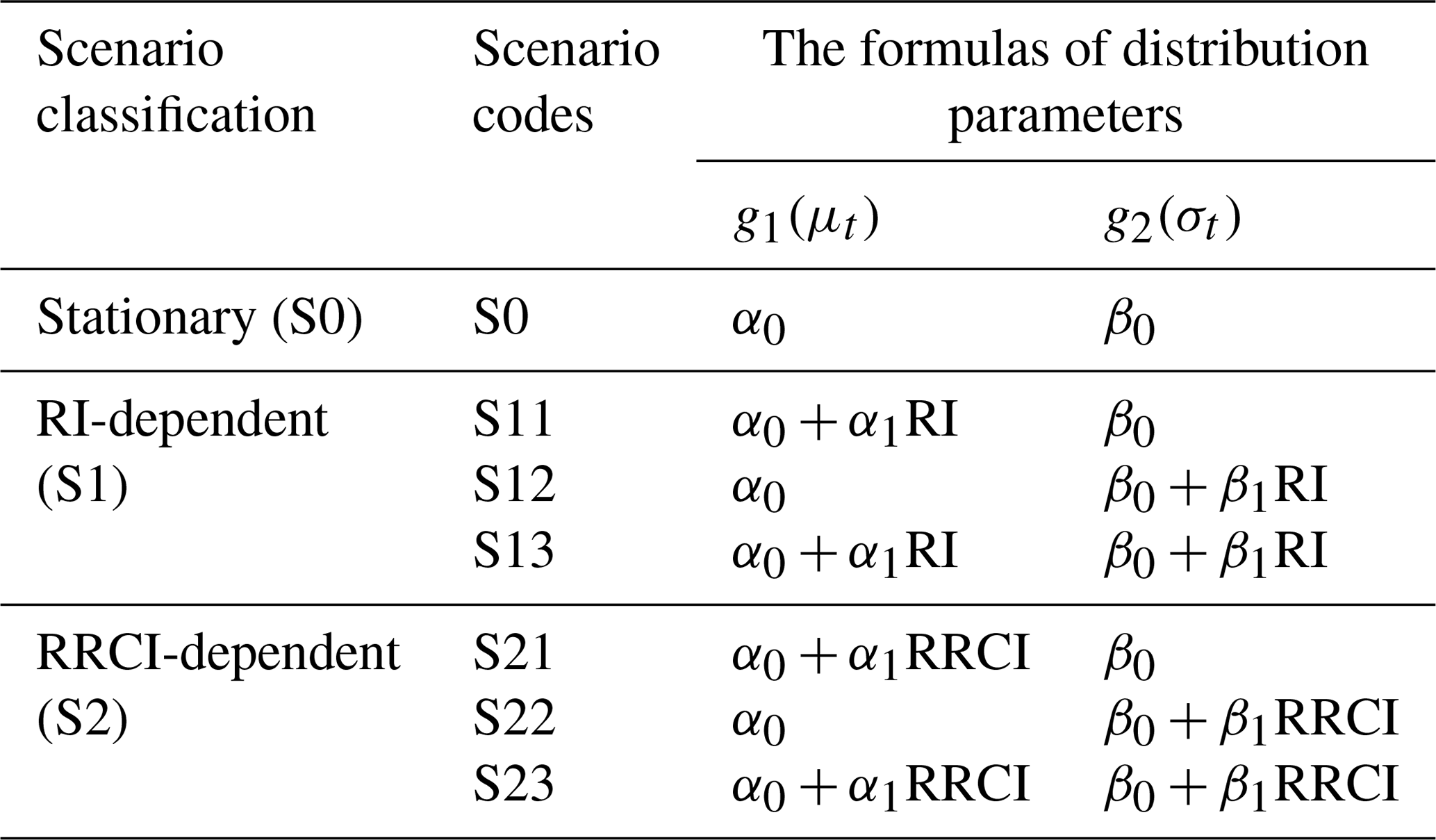
Suppose that the flood variable, Yt, obeys the distribution with the distribution parameters . In this study, only the distribution parameters μt and σt were allowed to be dependent on covariates because the shape parameter of the GEV is sensitive to the quantile estimation of rare events. According to the linear additive formulation of the generalized additive models for location, scale, and shape (GAMLSSs; Rigby and Stasinopoulos, 2005; Villarini et al., 2009), seven nonstationary scenarios for the formulas of the two distribution parameters, μt and σt, were investigated, as shown in Table 2. The constant scenario (S0) included one scenario (both μt and σt are constants). The RI-dependent scenarios (S1) included three scenarios: S11 (μt is RI-dependent and σt is constant), S12 (μt is constant and σt is RI-dependent), and S13 (both μt and σt are RI-dependent). In addition, the RRCI-dependent scenarios (S2) including S21, S22, and S23 are similar to S11, S12, and S13, respectively.
Table 2Seven nonstationary scenarios for the formulas of the two distribution parameters (i.e., μt and σt).
In the following, the Bayesian inference is introduced. The GEV_S23 (representing the nonstationary GEV distribution with the S23 scenario) model was used as an example, and the model parameter vector was used as the estimate. The Bayesian method was used to estimate θGEV_S23. Let the prior probability distribution be π(θGEV_S23) and the observations, D, have the likelihood l(D|θGEV_S23). Then the posterior probability distribution p(θGEV_S23|D) can be calculated using Bayes' theorem as follows:
where the integral is the normalizing constant, and Ω is the entire parameter space. The obvious difference between the Bayesian method and the frequentist method is that the Bayesian method considers the parameters θGEV_S23 to be random variables. In addition, the desired distribution of the random variables can be obtained using a Markov chain that can be constructed using various Markov chain Monte Carlo (MCMC) algorithms (Reis and Stedinger, 2005; Ribatet et al., 2007) to process Eq. (11). In addition, in this study, the Metropolis–Hastings algorithm was used (Chib and Greenberg, 1995; Viglione et al., 2013), which was done with the aid of the R package “MHadaptive” (Chivers, 2012). A beta-distribution function was used with the parameters u=6 and v=9 , which were suggested by Martins and Stedinger (2000, 2001) as the prior distribution on the shape parameter ξ. For the other model parameters, , and β1, the prior distributions were set to non-informative (flat) priors. There are two advantages of the Bayesian method. First, as noted by El Adlouni et al. (2007), this method allows the addition of other information, such as historical and regional information, by defining the prior distribution. Second, the Bayesian method can provide an explicit way to account for the uncertainty of parameters estimates. In the nonstationary case in the t year, the 95 % credible interval for the estimation of the flood quantile corresponding to a given probability, p , can be obtained from a set of stable parameters estimations, (), in which Mc is the length of the Markov chain.
The procedure of model selection can identify which of the five distributions is optimal and which of the seven nonstationary scenarios is optimal. If all the distribution parameters are identified as constants (S0), this process will be a stationary frequency analysis. To select the optimal model, the Schwarz Bayesian criterion (SBC; Schwarz, 1978) for each fitted model object is calculated by the following:
where is the maximized log likelihood of the model object, df is the degrees of freedom, and n is the number of data points. The SBC has a larger penalty on the overfitting phenomenon than the Akaike information criterion (AIC; Akaike, 1974). The model object with the lower SBC is preferred. The worm plot and the Q–Q plot were employed to check whether the model represented the data well.
3.1 Study area
The Han River (Fig. 4), with the coordinates of 30∘30′–34∘30′ N, 106∘00′–114∘00′ E, and a catchment area of 159 000 km2, is the largest tributary of the Yangtze River, China. This area has a warm, temperate, semi-humid, continental monsoon climate. The temperature in the basin is not much different from upstream to downstream. Although the elevation range of the study area is quite wide (13–3493 m), the study area is a rainfall-dominated area, and the snowmelt contribution is quite limited. The Ankang gauging station was used as an example. The timing of the AMDF is primarily during the major rainfall period from June to September (Fig. S3a, c, and d in the Supplement). In addition, the winter is warm, with mean temperature values of more than 2 ∘C, as shown in Fig. S3b. Since 1960, many reservoirs have been completed in the Han River basin. Information of the five major reservoirs is shown in Table 3, including the longitude, latitude, control area, time for completion, and capability. The Danjiangkou Reservoir in central China's Hubei province is the largest one in this basin and was completed by 1967. As a multi-purpose reservoir, it primarily aims to supply water and control floods, and it is also used for electricity generation and irrigation. The reservoir has a total storage capacity of 21.0 billion m3, a dead storage capacity of 7.23 billion m3, an effective storage capacity of 10.2 billion m3, and a flood control capacity of 7.72 billion m3. After the Danjiangkou Dam Extension Project in 2010, the Danjiangkou Reservoir gained an additional capacity of 13.0 billion m3 and an extra flood control storage capacity of 3.3 billion m3. In addition, this reservoir is operated using the strategy of staged increases in the flood limit water level during the flood control season (Zhang et al., 2009).
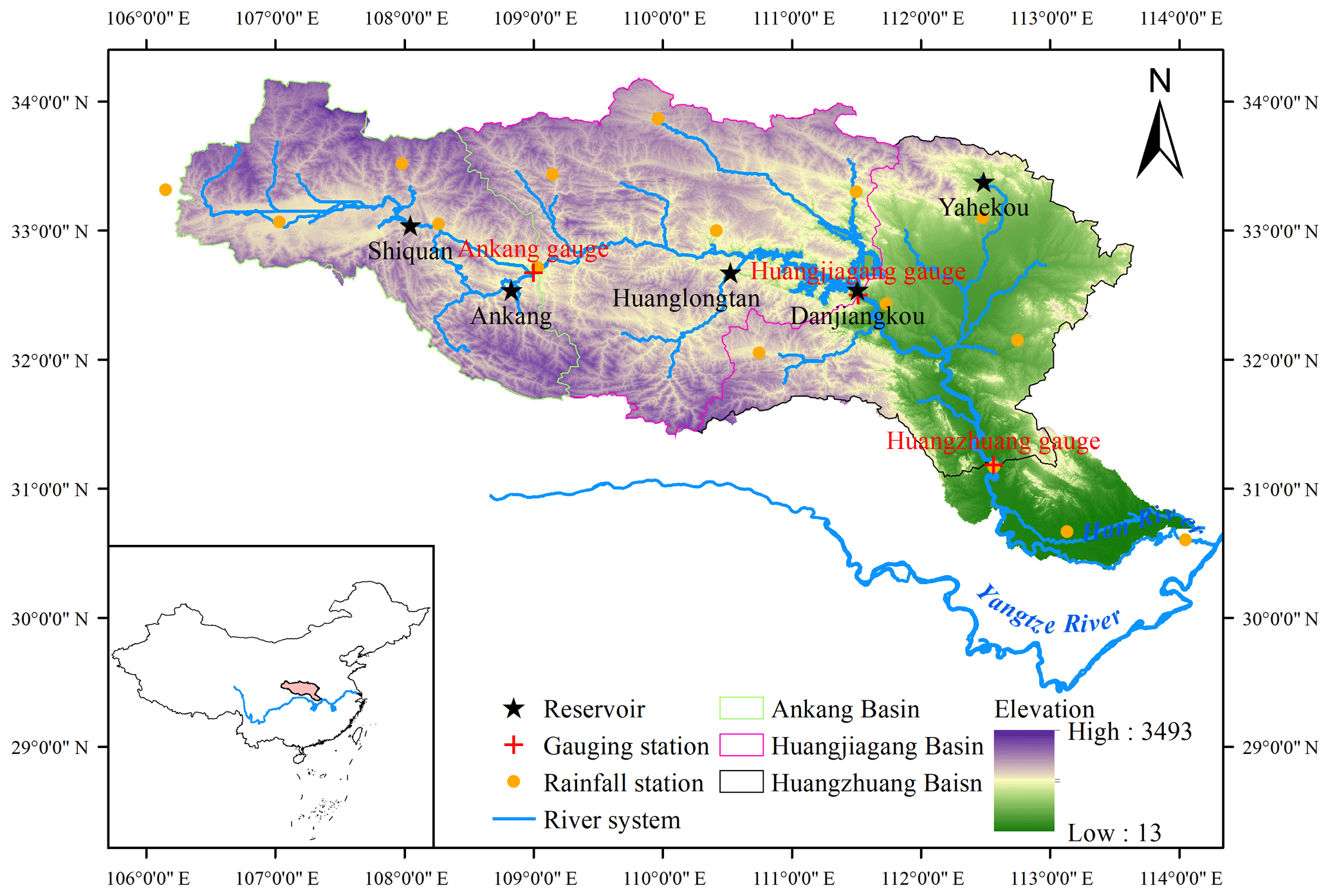
Figure 4Geographic location of the reservoirs, gauging stations, and rainfall stations along the Han River.
Table 3Information of the five major reservoirs in the Han River basin.

3.2 Data
The assessment analysis of reservoir effects on flood frequency utilized streamflow data, reservoir data, and rainfall data. The AMDF series was extracted from the daily streamflow records of the three gauges in the Han River basin; namely the Ankang (AK) station with a drainage area of 38 600 km2, the Huangjiagang (HJG) station with a drainage area of 90 491 km2, and the Huangzhuang (HZ) station with a drainage area of 142 056 km2. The streamflow and reservoir data were provided by the Hydrology Bureau of the Changjiang Water Resources Commission, China (http://www.cjh.com.cn/en/index.html, last access: 9 August 2019). The annual series of the maximum (M), the intensity (I), volume (V), the timing (T), and the distance (L) were extracted from the daily streamflow data to describe the MARI. Note that the timing of the MARI is equal to the occurrence time of the AMDF during the year. The MARI is an event averaged for the real values, and any 2 consecutive days of areal rainfall values in the MARI required more than 0.2 mm. Daily areal rainfall was calculated using the inverse distance weighting (IDW) method based on rainfall records from 16 stations (shown in Fig. 4). These rainfall data were downloaded from the National Climate Center of the China Meteorological Administration (source: http://www.cma.gov.cn/, last access: 9 August 2019). For the AK and HZ gauging stations, all the records were available from 1956 to 2015, while the HJG gauging station only had records available that were from 1956 to 2013.
4.1 Identification of reservoir effects
To confirm the impact of reservoirs on the AMDF in the study area, the mean and standard deviation of the AMDF before and after the construction of the two large reservoirs, the Danjiangkou Reservoir (1967) upstream of the HJG and HZ stations and the Ankang Reservoir (1992) upstream of the AK, HJG, and HZ stations, were compared. According to Table 4, the mean and standard deviation of the AMDF of the AK, HJG, and HZ stations were significantly reduced. By using the HJG station as an example, the mean of the AMDF (1992–2013) is 4139 m3 s−1, which is only 0.28 times 14 951 m3 s−1 (1956–1966), and the standard deviation is 4074 m3 s−1, approximately 0.52 times 7896 m3 s−1 (1956–1966).
Table 4Change in the mean and standard deviation of the AMDF after the construction of the two large reservoirs (Danjiangkou Reservoir, completed by 1967, and the Ankang Reservoir, finished by 1992).

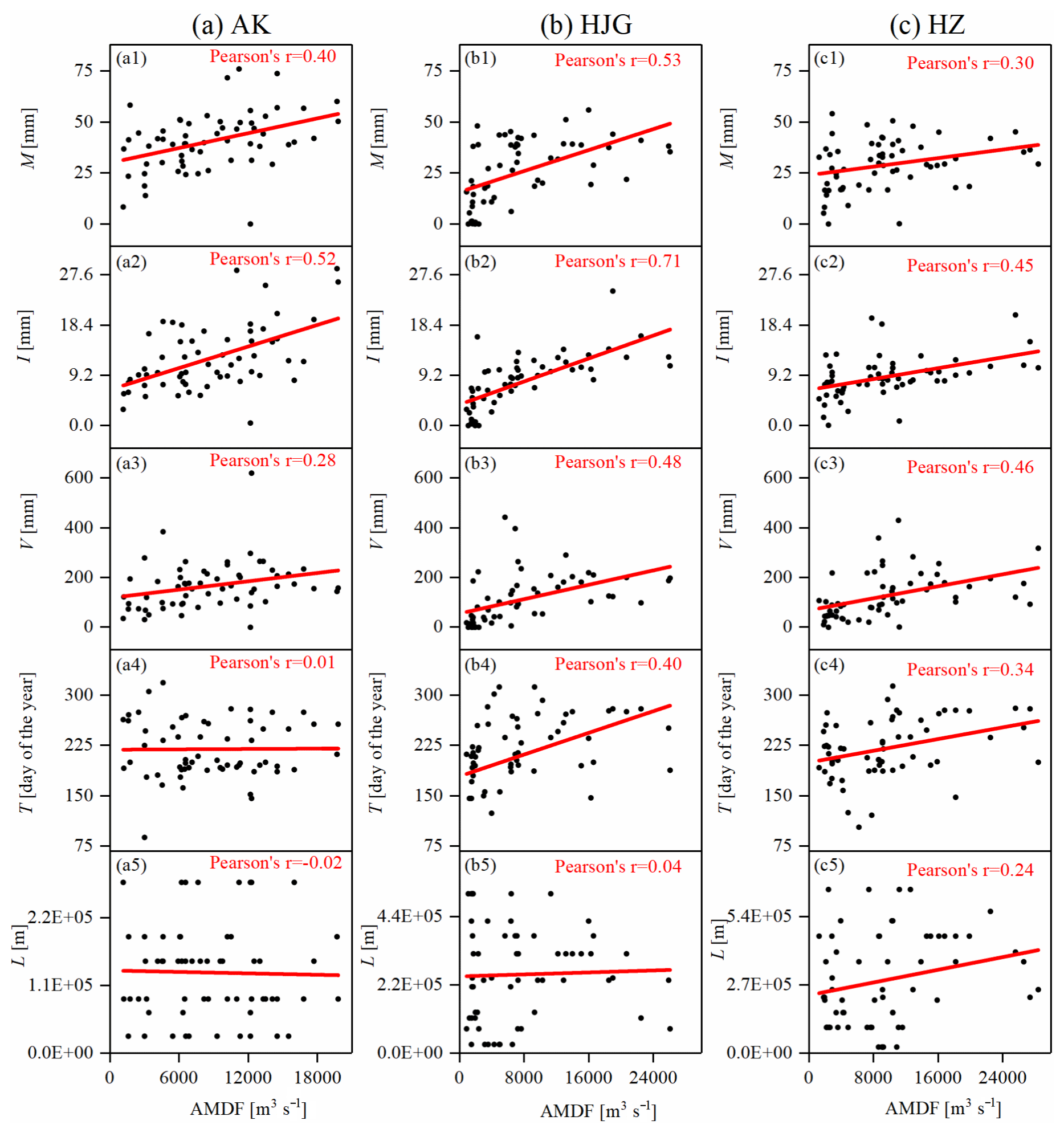
Figure 5Linear correlation between the five MARI variables and the AMDF for (a) the AK station, (b) the HJG station, and (c) the HZ station.
Figure 5 presents the linear correlation between the five MARI variables (i.e., the maximum, M; the intensity, I; volume, V; the timing, T; and the distance L) and the AMDF. It was found that for M, I, V, and T, except for T in the AK station, the Pearson correlation coefficients between these four variables and the AMDF range from 0.27 to 0.71 (p value <0.05), indicating that these four variables are significantly related to the AMDF. However, there is a Pearson correlation coefficient of no more than 0.24 between L and the AMDF for each of the stations. Thus, L was excluded from the calculation of the RRCI. A further analysis of the reservoir effects on the downstream AMDF will be performed in the following sections.
4.2 Results for the rainfall–reservoir composite index (RRCI)
To obtain the annual values of the RRCI, the RI was estimated first. The RI was affected by the loss of the reservoir capacity but not to a great extent (Fig. S2). This happened because the main reservoirs (Danjiangkou and Ankang reservoirs) had a small loss rate of no more than 15 % (Table S1 and Fig. S1).
Table 5Correlation coefficients between the RRCI and the AMDF. The values in bold font are the highest absolute values of Pearson, Kendall, or Spearman correlation coefficient for the station.

∗ The values in the first row are the correlation coefficients between RI and flood series.
The C-vine copula model was applied to calculate the OR-JEP of the scheduling-related MARI variables. In the modeling of the univariate marginal, the marginals of the intensity (I) of the AK and the HJG stations and the volume (V) of the HJG station were revised to deal with their significant change points (Table S2). To identify the scheduling-related variables from M, I, V, and T, the RRCI for all the possible subsets of M, I, V, and T was calculated and compared. The Pearson, Kendall, and Spearman correlation coefficients between the RRCI and the AMDF are listed in Table 5. Note that the entire decomposition structure of the C-vine copula for each RRCI of the same station was determined by the ordering of the variables of each subset (shown in the cells of the first column in Table 5). Figure 3 shows an example for the decomposition structure of the four-dimensional copula. As shown in the first row in Table 5, there is a negative correlation between the AMDF and the RI for each station. The values of the Pearson correlation coefficients between the AMDF and the RI for the AK, HJG, and HZ stations are −0.37, −0.55, and −0.53, respectively, demonstrating that there is a significant relation between the reservoir storage capacity and the reduction in the AMDF. For each station, with the exception of the RRCI of the one-dimensional case, the values of the Pearson, Kendall, and Spearman correlation coefficients between the RRCI and the AMDF are higher than between the RI and the AMDF. According to the highest Kendall correlation, the scheduling-related variables for the AK station were M, I, V, and T. Those for the HJG station were I and T, and those for the HZ station were I, V, and T.
Table 6Results of the copula models for scheduling-related rainfall variables.
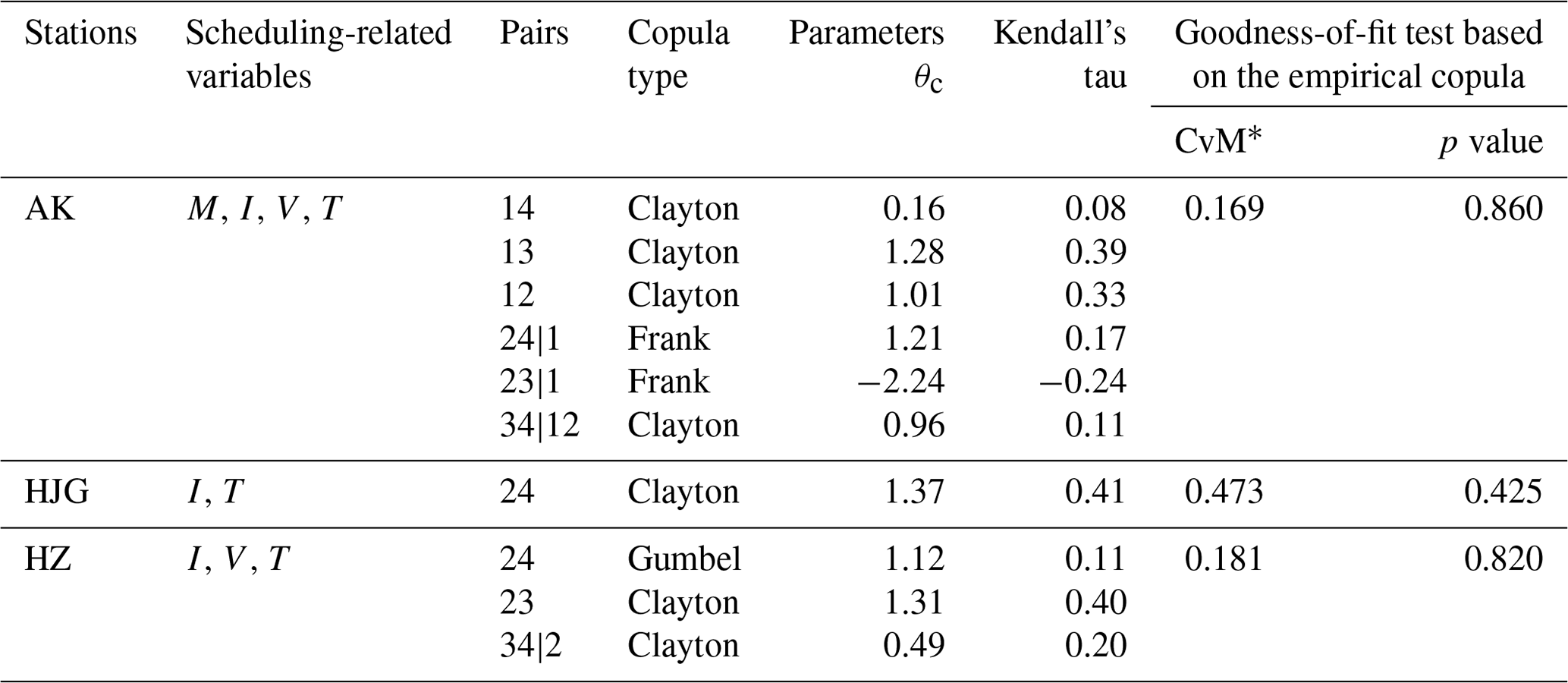
∗ CvM is the statistic of the Cramér–von Mises test. If the p value of the C-vine copula model is less than the significance level of 0.05, the model is not considered to be consistent with the empirical copula.
Table 6 shows the results of the copula modeling of the scheduling-related variables using the aid of the R package “VineCopula” (https://CRAN.R-project.org/package=VineCopula, last access: 9 August 2019). Note that for each bivariate pair in the third column in Table 6, three one-parameter bivariate Archimedean copula families (i.e., the Gumbel, Frank, and Clayton copulas; Nelsen, 2007) were used to select from. As shown in Table 6, the results of the Cramér–von Mises test (Genest et al., 2009) shows that all the C-vine copula models passed the test at a significance level of 0.05. This result indicated that these models were effective for simulating the joint distribution of the scheduling-related variables for the three stations. Finally, the variation in the RI and the RRCI over time is displayed in Fig. 6. It can be seen that for each station, after reservoir construction, in most cases, the annual values of the RRCI are larger (close to 1) than those of the RI. In contrast, in a few cases, such as in 1983 at the HZ and HJG stations, the RRCI values were lower than the RI values.

Figure 6Variation of the RI and the RRCI for (a) the AK station, (b) the HJG station, and (c) the HZ station.
4.3 Flood frequency analysis
A nonstationary flood frequency analysis using the RRCI or the RI as the covariate was performed to investigate how the reservoirs affected the downstream flood frequency. A summary of results of fitting the nonstationary models to the flood data is shown in Table 7. Based on the SBC, the lowest values indicate that the best models for the AK, HJG, and HZ stations are the nonstationary WEI distribution with S23, the nonstationary GA distribution with S21, and the nonstationary WEI distribution with S21, respectively, hereafter referred to as WEI_S23, GA_S21, and WEI_S21, respectively. Note that for any one of the five distributions (GA, WEI, LOGNO, GU, and GEV), the RRCI-dependent scenario had a lower SBC value than the RI-dependent scenario for each gauging station. Furthermore, for the RI-dependent and RRCI-dependent scenarios, using the HZ station as an example, the optimal formulas of the two distribution parameters, μt and σt, are given as follows:
-
WEI_S11
-
WEI_S21
It was found that in Eqs. (13) and (14), there were negative estimates of −2.79 and −1.42 for α1, respectively, revealing the decreasing degree of the frequency and magnitude of downstream floods due to the reservoir effects.
Table 7Summary of the results of the nonstationary flood distribution models. The value in bold font is the lowest SBC value for the station.
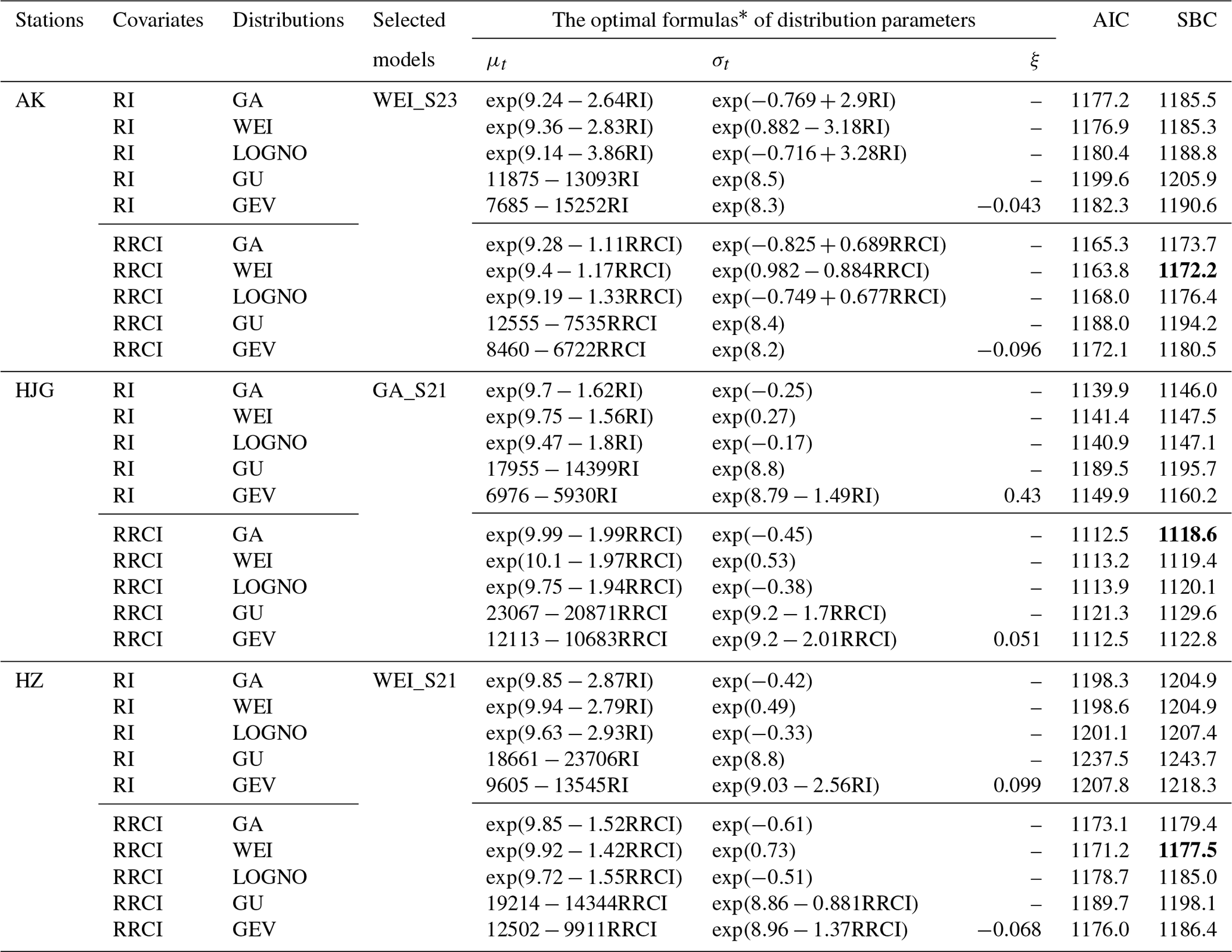
∗ The model parameters in the optimal formulas are the posterior mean from the Bayesian inference.
Figure 7 compares the stationary scenario (S0), the RI-dependent scenario (S1), and the RRCI-dependent scenario (S2) of the same optimal distributions that explain all the flood values and the several largest flood values for each station. The Q–Q plots (Fig. 7a1–c1) show that overall, the RRCI-dependent scenario more adequately captured the entire empirical quantiles (particularly the smallest and largest empirical quantiles) than the two other scenarios for each station. Furthermore, as shown in Fig. 7a2–c2, for the seven largest floods (observed) of each station, the RRCI-dependent scenario produced lower quantile residuals than the two other scenarios.
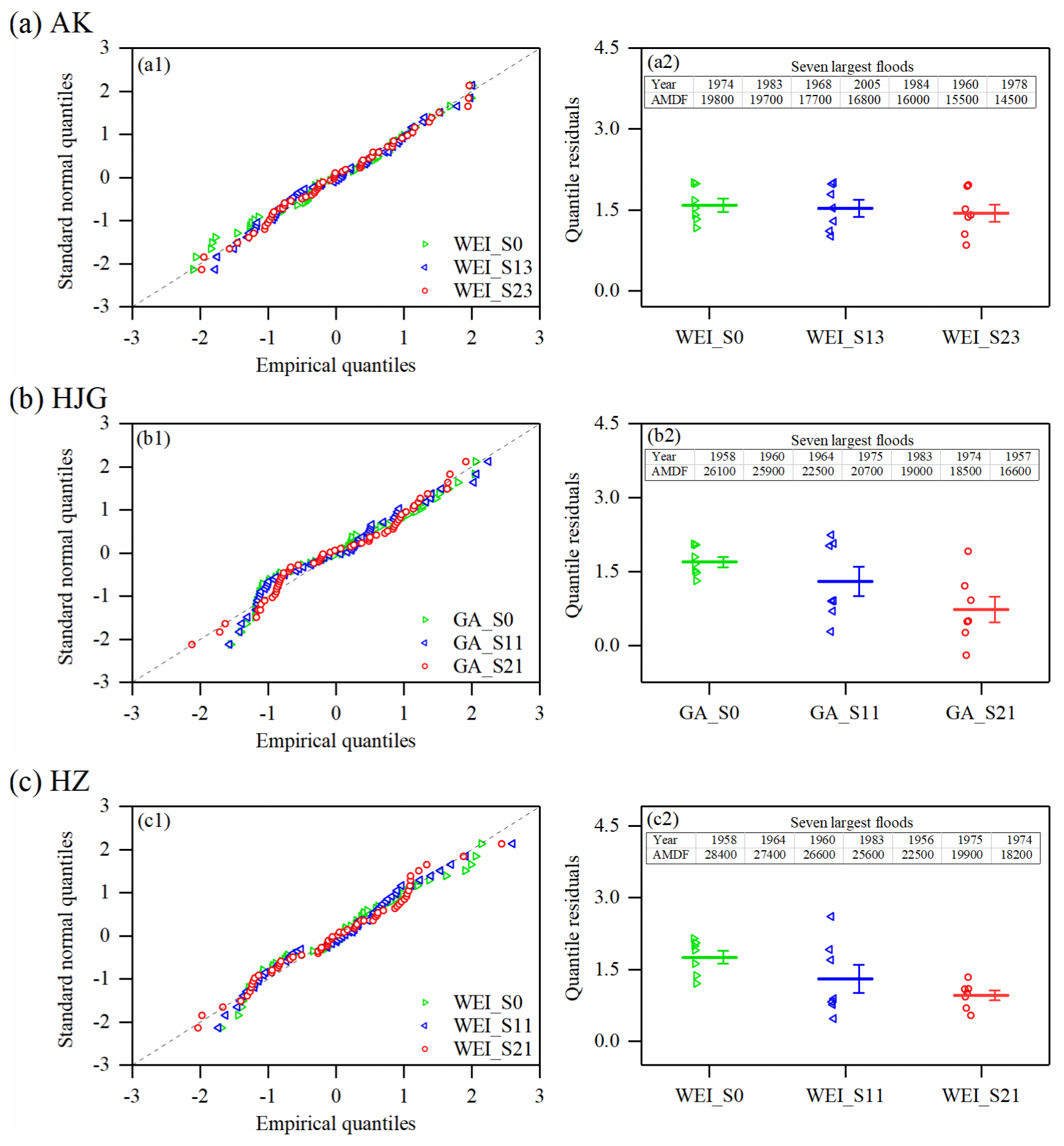
Figure 7Comparison of the stationary (S0), the RI-dependent (S1), and the RRCI-dependent (S2) scenarios of the same optimal distributions for (a) the AK station, (b) the HJG station, and (c) the HZ station. The left panels (a1, b1, c1) are the Q–Q plots for the entire AMDF series in each station. The right panels (a2, b2, c2) are the plots of the quantile residuals for the seven largest floods (their values and occurrence years have been listed) in each station, and the means of their quantile residuals (points) and the corresponding standard errors are indicated by the lines.
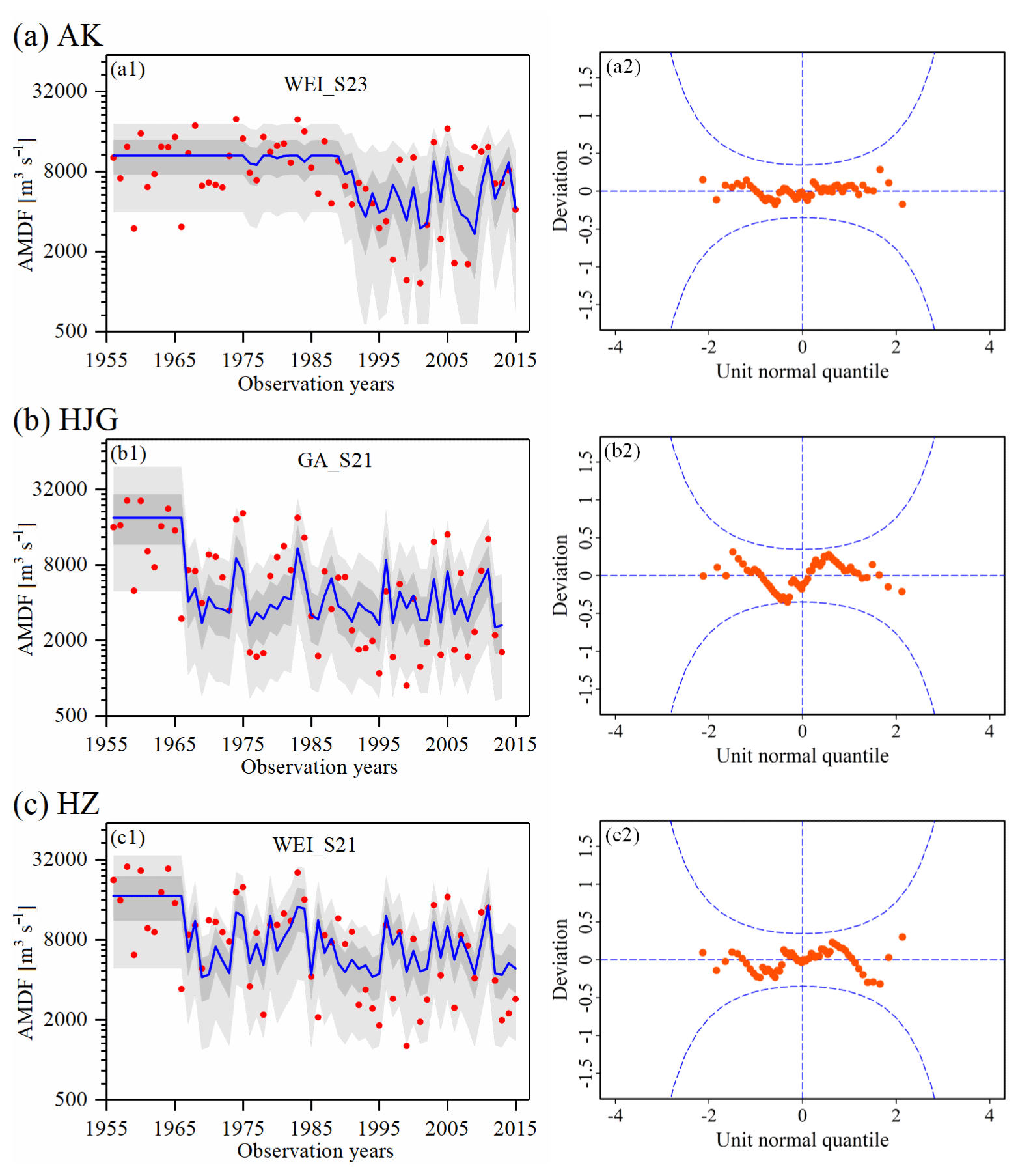
Figure 8Performance of (a) WEI_S23 for the AK station, (b) GA_S21 for the HJG station, and (c) WEI_S21 for the HZ station. The left panels (a1, b1, c1) are the centile-curve plots in each station (the 50th centile curves are indicated by the thick blue lines, the light grey-filled areas are between the 5th and 95th centile curves, the dark grey-filled areas are between the 25th and 75th centile curves, and the filled red points indicate the observed series). The right panels (a2, b2, c2) are the worm plots. In a reasonable model, the plotted points should be within the 95 % confidence intervals (between the two blue dashed curves).
Figure 8 shows the performance of the best models: WEI_S23 for the AK station, GA_S21 for the HJG station, and WEI_S21 for the HZ station. The points in the worm plots in Fig. 8 are within the 95 % confidence interval, indicating that the selected models are reasonable. In addition, according to the centile-curve plots in Fig. 8, the AMDF series is well fitted by the best models. Undoubtedly, with the incorporation of the effects of the MARI, the RRCI-dependent scenario captured the presence of nonstationarity in the downstream flood frequency well. The case of the HZ station was used for the analysis (Fig. 8c1). After the construction of the Danjiangkou Reservoir (1967), due to reservoir operation, most of the values of the AMDF had been reduced in magnitude by this reservoir. However, some relatively large flood events still occurred several times, such as 25 600 m3 s−1 in 1983 and 19 900 m3 s−1 in 1975. Obviously, this phenomenon of flood occurrences was explained well by the RRCI.

Figure 9Statistical inference of the 100-year return levels with a 95 % uncertainty interval using the optimal RI-dependent and the RRCI-dependent distributions: (a) WEI_S13 and WEI_S23 for the AK station, (b) GA_11 and GA_S21 for the HJG station, and (c) WEI_S11 and WEI_S21 for the HZ station. In nonstationary case, the 95 % credible interval in the t year is calculated by a set of the (99th) percentile estimations, which are obtained by the flood distribution functions determined by the values of both covariate in that year and posterior parameter samples.
The 100-year return levels at a 95 % credible interval from WEI_S23 and WEI_S13 for the AK station, GA_S21 and GA_S11 for the HJG station, and WEI_S21 and WEI_S11 for the HZ station are presented in Fig. 9. For each station, compared to the optimal RI-dependent distribution, the optimal RRCI-dependent distribution provided a lower 100-year return level. However, exceptions existed. In addition, after the construction of the main reservoir, the uncertainty range of the AK station was larger than that of the HJG and HZ stations. A possible explanation for the larger uncertainty range was that the sample size (1993–2015) of the regulated floods at the AK station was smaller. Furthermore, the dependent relationship between the RRCI and the AMDF at the AK station was weaker.
4.4 Discussion
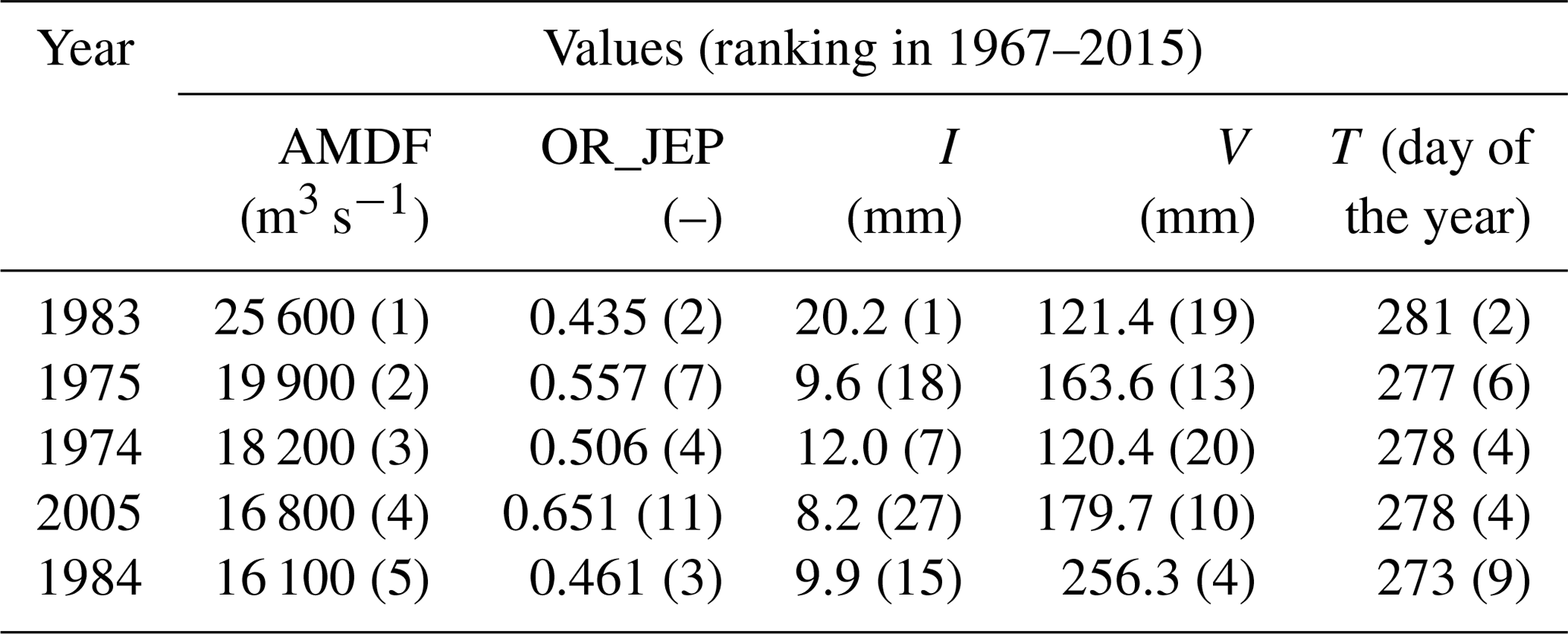
The long-term variation in the AMDF series (Fig. 8) indicates that the upstream reservoirs had evidently altered the downstream flood regimes. As an example, since the completion of the Danjiangkou Reservoir in 1967, the flood magnitude of the HZ station was evidently reduced overall. This is consistent with the results of the effects of reservoirs on the hydrological regime in this area found in previous studies (Cong et al., 2013; Guo et al., 2008; Jiang et al., 2014; Lu et al., 2009). In this study, it was found that there was a significant difference between downstream floods affected by the same reservoir system (with the same RI value). In most cases, relatively small downstream floods were obtained. However, it is of interest to note that unexpected large downstream floods still occurred in a few cases in spite of a large RI value. For example, most values of the AMDF in the HZ station have been less 10 000 m3 s−1 since 1967, but the values of the AMDF in 1983 and in 1975 were 25 600 and 19 900 m3 s−1, respectively. These unexpected large downstream floods were probably related to the MARI effects on reservoir operation. The five largest (unexpected) floods since 1967 and the corresponding values of the scheduling-related MARI variables in the HZ station are shown in Table 8. It was found that the largest floods from 1967 to 2015 occurred in 1983. For this flood event, the MARI was a rare event (with an OR-JEP value of 0.435 ranking second in 1967–2015) due to the largest mean intensity (I=20.2 mm) and the second latest occurrence (T=281). Surprisingly, all the timing values of the MARI for these five unexpected downstream floods showed high rankings (second to ninth). These timing values were near the end (approximately the 300th day of the year) of the flood control period (July–October) in this area. Actually, near the end of the major flood control period, the storage capacity should be decreased. This is because according to the operation rules of the Danjiangkou Reservoir (Zhang et al., 2009), there is a staged increasing flood limit water level during the flood control season. One important cause for those unexpected large downstream floods was probably that the remaining storage capacity at the end of flood season was not sufficient to reduce some late floods. Therefore, in addition to the storage capacity of reservoirs, the MARI effects should be indispensably considered when attempting to accurately quantify the effects of the reservoir on downstream floods.
Table 8Summary of the rainfall information for the five largest floods after the construction (1967) of the Danjiangkou Reservoir in the HZ station.
With the combination of both the RI and the OR-JEP, the RRCI had a significant difference from RI (Fig. 6). With a few exceptions, the RRCI values were higher than the RI values. This indicates that the real reservoir impact may be underestimated by the RI in most cases. Moreover, the RI will also probably overestimate the real reservoir impact in a few cases because of not considering special rainfall events (i.e., the MARI with low values of the OR-JEP). The results of the covariate-based nonstationary flood frequency analysis (Table 7 and Figs. 7 and 8) demonstrate that, compared to the RI-dependent scenario, the RRCI-dependent scenario for the optimal nonstationary distribution more completely captured the presence of nonstationarity in the downstream flood frequency. Therefore, the RRCI might be a useful index for accessing the reservoir effects on downstream flood frequency.
Finally, the estimation errors of the OR-JEP should be noted. (1) Only those MARI samples that corresponded to the timing of the AMDF were included to estimate the OR-JEP. This means that some extreme MARI samples that corresponded to the non-maximum flow were not included, resulting in an estimation error for the OR-JEP. To reduce this error, it might be worth considering the use of the peaks-over-threshold sampling method. (2) The areal-averaged MARI was based on the records from 16 rainfall stations using the IDW method. The estimation error of the areal-averaged rainfall can be transferred to the OR-JEP estimation error. Additional rainfall site data and spatial distribution information were needed to reduce the OR-JEP estimation error. Nonetheless, the good performance of the downstream flood frequency model results demonstrated that the MARI samples still remained representative in this study.
Accurately assessing the impact of reservoirs on downstream floods is an important issue for flood risk management. In this study, to evaluate the effects of reservoirs on the downstream flood frequency of the Han River, the rainfall–reservoir composite index (RRCI) was derived from Eq. (2), which considers the combination of the reservoir index (RI) and the OR joint exceedance probability (OR-JEP) of scheduling-related rainfall variables. The main findings are summarized as follows. (1) The magnitude of the downstream flood events has been reduced by the reservoir system in the study area. However, the long-term variation in the observed AMDF series showed that despite the large reservoirs, unexpected large flood events still occurred several times, such as at the Huangzhuang station in 1983. One important cause of the unexpected large floods at the Huangzhuang station may have been related to the operation strategy of staged increases in the flood limit water level of the Danjiangkou Reservoir. (2) According to the results of the covariate-based nonstationary flood frequency analysis for each station, compared to the optimal RI-dependent distribution, the optimal RRCI-dependent distribution more completely captured the presence of nonstationarity in the downstream flood frequency. (3) Furthermore, in estimating the 100-year return level for each station, the optimal RRCI-dependent distribution provided a lower 100-year return level, but exceptions existed. In addition, it provided a smaller uncertainty range associated with the uncertainty of the model parameter.
Consequently, this study demonstrated the necessity of including the antecedent rainfall effects, in addition to the effects of reservoir storage capacity, on reservoir operation to assess the reservoir effects on downstream flood frequency. This study provides a comprehensive approach for downstream flood risk management under the impacts of reservoirs.
The data used in this paper can be requested by contacting the corresponding author Lihua Xiong at xionglh@whu.edu.cn.
The supplement related to this article is available online at: https://doi.org/10.5194/hess-23-4453-2019-supplement.
BX and LX conceived and designed the study. LX, JX, and CYX provided funding. BX, LX, and CJ provided the methodology. BX and LX conducted case analysis. BX wrote the original draft. LX, JX, CYX, and TD reviewed and edited the paper. All authors read and approved the paper.
The authors declare that they have no conflict of interest.
We greatly appreciate the editor and the two reviewers for their insightful comments and constructive suggestions for improving the paper.
This research has been supported by the National Natural Science Foundation of China (grant nos. 41890822 and 51525902), the Research Council of Norway (FRINATEK project 274310), and the “Plan 111” Fund of the Ministry of Education of China (grant no. B18037).
This paper was edited by Jim Freer and reviewed by two anonymous referees.
Aas, K., Czado, C., Frigessi, A., and Bakken, H.: Pair-copula constructions of multiple dependence, Insur. Math. Econ., 44, 182–198, https://doi.org/10.1016/j.insmatheco.2007.02.001, 2009.
Akaike, H.: A new look at the statistical model identification, IEEE T. Automat. Contr., 19, 716–723, https://doi.org/10.1109/TAC.1974.1100705, 1974.
Ayalew, T. B., Krajewski, W. F., and Mantilla, R.: Exploring the effect of reservoir storage on peak discharge frequency, J. Hydrol. Eng., 18, 1697–1708, https://doi.org/10.1061/(ASCE)HE.1943-5584.0000721, 2013.
Ayalew, T. B., Krajewski, W. F., and Mantilla, R.: Inights into expected changes in regulated flood frequencies due to the spatial configuration of flood retention ponds, J. Hydrol. Eng., 20, 04015010, https://doi.org/10.1061/(ASCE)HE.1943-5584.0001173, 2015.
Batalla, R. J., Gomez, C. M., and Kondolf, G. M.: Reservoir-induced hydrological changes in the Ebro River basin (NE Spain), J. Hydrol., 290, 117–136, https://doi.org/10.1016/j.jhydrol.2003.12.002, 2004.
Benito, G. and Thorndycraft, V. R.: Palaeoflood hydrology and its role in applied hydrological sciences, J. Hydrol., 313, 3–15, https://doi.org/10.1016/j.jhydrol.2005.02.002, 2005.
Chib, S. and Greenberg, E.: Understanding the metropolis-hastings algorithm, Am. Stat., 49, 327–335, https://doi.org/10.1080/00031305.1995.10476177, 1995.
Chivers, C.: MHadaptive: General Markov chain Monte Carlo for Bayesian inference using adaptive Metropolis-Hastings sampling, available at: https://CRAN.R-project.org/package=MHadaptive (last access: 9 August 2019), 2012.
Coles, S.: An Introduction to Statistical Modeling of Extreme Values, Springer, London, https://doi.org/10.1007/978-1-4471-3675-0, 2001.
Cong, M., Chunxia, L., and Yiqiu, L.: Runoff change in the lower reaches of Ankang Reservoir and the influence of Ankang Reservoir on its downstream, Resources and Environment in the Yangtze Basin, 22, 1433–1440, 2013 (in Chinese).
Du, T., Xiong, L., Xu, C.-Y., Gippel, C. J., Guo, S., and Liu, P.: Return period and risk analysis of nonstationary low-flow series under climate change, J. Hydrol., 527, 234–250, https://doi.org/10.1016/j.jhydrol.2015.04.041, 2015.
El Adlouni, S., Ouarda, T. B. M. J., Zhang, X., Roy, R., and Bobée, B.: Generalized maximum likelihood estimators for the nonstationary generalized extreme value model, Water Resour. Res., 43, 455–456, https://doi.org/10.1029/2005WR004545, 2007.
Genest, C., Rémillard, B., and Beaudoin, D.: Goodness-of-fit tests for copulas: A review and a power study, Insur. Math. Econ., 44, 199–213, https://doi.org/10.1016/j.insmatheco.2007.10.005, 2009.
Gilroy, K. L. and Mccuen, R. H.: A nonstationary flood frequency analysis method to adjust for future climate change and urbanization, J. Hydrol., 414, 40–48, https://doi.org/10.1016/j.jhydrol.2011.10.009, 2012.
Goel, N. K., Kurothe, R. S., Mathur, B. S., and Vogel, R. M.: A derived flood frequency distribution for correlated rainfall intensity and duration, Water Resour. Res., 33, 2103–2107, https://doi.org/10.1029/97WR00812, 1997.
Graf, W. L.: Dam nation: A geographic census of American dams and their large-scale hydrologic impacts, Water Resour. Res., 35, 1305–1311, https://doi.org/10.1029/1999WR900016, 1999.
Guo, W., Xia, Z., and Wang, Q.: Effects of Danjiangkou Reservoir on hydrological regimes in the middle and lower reaches of Hanjiang River, Journal of Hohai University (Natural Sciences), 36, 733–737, 2008 (in Chinese).
Jiang, C., Xiong, L., Xu, C.-Y., and Guo, S.: Bivariate frequency analysis of nonstationary low-flow series based on the time-varying copula, Hydrol. Process., 29, 1521–1534, https://doi.org/10.1002/hyp.10288, 2014.
Kwon, H.-H., Brown, C., and Lall, U.: Climate informed flood frequency analysis and prediction in Montana using hierarchical Bayesian modeling, Geophys. Res. Lett., 35, L05404, https://doi.org/10.1029/2007GL032220, 2008.
Lee, J., Heo, J.-H., Lee, J., and Kim, N.: Assessment of flood frequency alteration by dam construction via SWAT simulation, Water, 9, 264, https://doi.org/10.3390/w9040264, 2017.
Liang, Z., Yang, J., Hu, Y., Wang, J., Li, B., and Zhao, J.: A sample reconstruction method based on a modified reservoir index for flood frequency analysis of non-stationary hydrological series, Stoch. Env. Res. Risk A., 32, 1561–1571, https://doi.org/10.1007/s00477-017-1465-1, 2018.
López, J. and Francés, F.: Non-stationary flood frequency analysis in continental Spanish rivers, using climate and reservoir indices as external covariates, Hydrol. Earth Syst. Sci., 17, 3189–3203, https://doi.org/10.5194/hess-17-3189-2013, 2013.
Lu, G., Liu, Y., Zou, X., Zou, Z., and Cai, T.: Impact of the Danjiangkou Reservoir on the flow regime in the middle and lower reaches of Hanjiang River, Resources and Environment in the Yangtze Basin, 18, 959–963, 2009 (in Chinese).
Magilligan, F. J. and Nislow, K. H.: Changes in hydrologic regime by dams, Geomorphology, 71, 61–78, https://doi.org/10.1016/j.geomorph.2004.08.017, 2005.
Martins, E. S. and Stedinger, J. R.: Generalized maximum-likelihood generalized extreme-value quantile estimators for hydrologic data, Water Resour. Res., 36, 737–744, https://doi.org/10.1029/1999WR900330, 2000.
Martins, E. S. and Stedinger, J. R.: Generalized maximum likelihood Pareto-Poisson estimators for partial duration series, Water Resour. Res., 37, 2551–2557, 2001.
Mei, X., Dai, Z., van Gelder, P. H. A. J. M., and Gao, J.: Linking Three Gorges Dam and downstream hydrological regimes along the Yangtze River, China, Earth Space Sci., 2, 94–106, https://doi.org/10.1002/2014EA000052, 2015.
Milly, P. C. D., Betancourt, J., Falkenmark, M., Hirsch, R. M., Kundzewicz, Z. W., Lettenmaier, D. P., and Stouffer, R. J.: Stationarity Is Dead: Whither Water Management?, Science, 319, 573–574, https://doi.org/10.1029/2001WR000367, 2008.
Nelsen, R.: An Introduction to Copulas. Springer Science & Business Media, New York, USA, 2007.
Ouarda, T. and El-Adlouni, S.: Bayesian nonstationary frequency analysis of hydrological variables 1, J. Am. Water Resour. As., 47, 496–505, https://doi.org/10.1111/j.1752-1688.2011.00544.x, 2011.
Pettitt, A. N.: A non-parametric approach to the change-point problem, J. R. Stat. Soc., 28, 126–135, 1979.
Reis Jr., D. S. and Stedinger, J. R.: Bayesian MCMC flood frequency analysis with historical information, J. Hydrol., 313, 97–116, https://doi.org/10.1016/j.jhydrol.2005.02.028, 2005.
Ribatet, M., Sauquet, E., Grésillon, J.-M., and Ouarda, T. B.: Usefulness of the reversible jump Markov chain Monte Carlo model in regional flood frequency analysis, Water Resour. Res., 43, W08403, https://doi.org/10.1029/2006WR005525, 2007.
Rigby, R. A. and Stasinopoulos, D. M.: Generalized additive models for location, scale and shape, J. R. Stat. Soc. C.-Appl., 54, 507–554, https://doi.org/10.1111/j.1467-9876.2005.00510.x, 2005.
Salas, J. D.: Analysis and modeling of hydrologic time series, Handbook of Hydrology, chap. 19, McGraw Hill, New York, USA, 1–72, 1993.
Scarf, P.: Estimation for a four parameter generalized extreme value distribution, Commun. Stat.-Theor. M., 21, 2185–2201, https://doi.org/10.1080/03610929208830906, 1992.
Schwarz, G.: Estimating the dimension of a model, Ann. Stat., 6, 461–464, 1978.
Sklar, M.: Fonctions de repartition an dimensions et leurs marges, Publications de l'Institut Statistique de l'Université de Paris, 8, 229–231, 1959.
Su, C. and Chen, X.: Assessing the effects of reservoirs on extreme flows using nonstationary flood frequency models with the modified reservoir index as a covariate, Adv. Water Resour., 124, 29–40, https://doi.org/10.1016/j.advwatres.2018.12.004, 2019.
Viglione, A., Merz, R., Salinas, J. L., and Blöschl, G.: Flood frequency hydrology: 3. A Bayesian analysis, Water Resour. Res., 49, 675–692, https://doi.org/10.1029/2011WR010782, 2013.
Villarini, G., Smith, J. A., Serinaldi, F., Bales, J., Bates, P. D., and Krajewski, W. F.: Flood frequency analysis for nonstationary annual peak records in an urban drainage basin, Adv. Water Resour., 32, 1255–1266, https://doi.org/10.1016/j.advwatres.2009.05.003, 2009.
Volpi, E., Di Lazzaro, M., Bertola, M., Viglione, A., and Fiori, A.: Reservoir effects on flood peak discharge at the catchment scale, Water Resour. Res., 54, 9623–9636, https://doi.org/10.1029/2018WR023866, 2018.
Wang, W., Li, H. Y., Leung, L. R., Yigzaw, W., Zhao, J., Lu, H., Deng, Z., Demisie, Y., and Blöschl, G.: Nonlinear filtering effects of reservoirs on flood frequency curves at the regional scale, Water Resour. Res., 53, 8277–8292, https://doi.org/10.1002/2017WR020871, 2017.
Wyżga, B., Kundzewicz, Z. W., Ruiz-Villanueva, V., and Zawiejska, J.: Flood generation mechanisms and changes in principal drivers, in: Flood Risk in the Upper Vistula Basin, Springer, Cham, Switzerland, 2016.
Xiong, B., Xiong, L., Chen, J., Xu, C.-Y., and Li, L.: Multiple causes of nonstationarity in the Weihe annual low-flow series, Hydrol. Earth Syst. Sci., 22, 1525–1542, https://doi.org/10.5194/hess-22-1525-2018, 2018.
Xiong, L., Jiang, C., Xu, C.-Y., Yu, K. X., and Guo, S.: A framework of change-point detection for multivariate hydrological series, Water Resour. Res., 51, 8198–8217, https://doi.org/10.1002/2015WR017677, 2015.
Yan, L., Xiong, L., Liu, D., Hu, T., and Xu, C. Y.: Frequency analysis of nonstationary annual maximum flood series using the time-varying two-component mixture distributions, Hydrol. Process., 31, 69–89, https://doi.org/10.1002/hyp.10965, 2017.
Yang, T., Zhang, Q., Chen, Y. D., Tao, X., Xu, C. Y., and Chen, X.: A spatial assessment of hydrologic alteration caused by dam construction in the middle and lower Yellow River, China, Hydrol. Process., 22, 3829–3843, https://doi.org/10.1002/hyp.6993, 2008.
Zhang, L., Xu, J., Huo, J., and Chen, J.: Study on stage flood control water level of Danjiangkou Reservoir, Journal of Yangtze River Scientific Research Institute, 26, 13–16, 2009 (in Chinese).
Zhang, Q., Gu, X., Singh, V. P., Xiao, M., and Chen, X.: Evaluation of flood frequency under non-stationarity resulting from climate indices and reservoir indices in the East River basin, China, J. Hydrol., 527, 565–575, https://doi.org/10.1016/j.jhydrol.2015.05.029, 2015.