the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 14 Jan 2020
| 14 Jan 2020
Temporal rainfall disaggregation using a micro-canonical cascade model: possibilities to improve the autocorrelation
Hannes Müller-Thomy
In urban hydrology rainfall time series of high resolution in time are crucial. Such time series with sufficient length can be generated through the disaggregation of daily data with a micro-canonical cascade model. A well-known problem of time series generated in this way is the inadequate representation of the autocorrelation. In this paper two cascade model modifications are analysed regarding their ability to improve the autocorrelation in disaggregated time series with 5 min resolution. Both modifications are based on a state-of-the-art reference cascade model (method A). In the first modification, a position dependency is introduced in the first disaggregation step (method B). In the second modification the position of a wet time step is redefined in addition by taking into account the disaggregated finer time steps of the previous time step instead of the previous time step itself (method C). Both modifications led to an improvement of the autocorrelation, especially the position redefinition (e.g. for lag-1 autocorrelation, relative errors of −3 % (method B) and 1 % (method C) instead of −4 % for method A). To ensure the conservation of a minimum rainfall amount in the wet time steps, the mimicry of a measurement device is simulated after the disaggregation process. Simulated annealing as a post-processing strategy was tested as an alternative as well as an addition to the modifications in methods B and C. For the resampling, a special focus was given to the conservation of the extreme rainfall values. Therefore, a universal extreme event definition was introduced to define extreme events a priori without knowing their occurrence in time or magnitude. The resampling algorithm is capable of improving the autocorrelation, independent of the previously applied cascade model variant (e.g. for lag-1 autocorrelation the relative error of −4 % for method A is reduced to 0.9 %). Also, the improvement of the autocorrelation by the resampling was higher than by the choice of the cascade model modification. The best overall representation of the autocorrelation was achieved by method C in combination with the resampling algorithm. The study was carried out for 24 rain gauges in Lower Saxony, Germany.
- Article
(4608 KB) -
Supplement
(327 KB) - BibTeX
- EndNote





For many applications in hydrology high-resolution rainfall time series are crucial (see the review of Cristiano et al., 2017) to match the scale of the underlying processes (Blöschl and Sivapalan, 1995). Schilling (1991) concludes that for urban hydrology, in particular for overland flow, a temporal resolution of 5 min is acceptable. Berne et al. (2004) point out that the required temporal resolution depends on the catchment size and recommend for urban catchments with area sizes of about 1000 ha a temporal resolution of 6 min and for 10 ha or smaller a temporal resolution of 1 min. Unfortunately, lengths of time series with such a high temporal resolution are insufficient for most applications. However, for the non-recording stations (registration of daily values) the time series lengths are usually sufficient, but the temporal resolution is not fine enough to cope with the dynamics in urban hydrology (Ochoa-Rodriguez et al., 2015). A possible solution for this data scarcity is rainfall disaggregation. Information of short, high-resolution time series is used to disaggregate coarser time series. The disaggregation results in high-resolution time series with sufficient lengths as well as a higher network density in most cases. Several methods exist for the temporal disaggregation, e.g. method of fragments (Wójcik and Buishand, 2003; Westra et al., 2012; Breinl et al., 2015; Breinl and Di Baldassarre, 2019), rectangular pulse models (Koutsoyiannis and Onof, 2001) and cascade models. Cascade models are well-known disaggregation models for the generation of high-resolution rainfall time series and were developed originally in the field of turbulence theory (Mandelbrot, 1974). Based on Koutsoyiannis and Langousis (2011), the canonical version of the cascade model (conservation of rainfall amount on average during the disaggregation, e.g. Molnar and Burlando, 2005; Paschalis et al., 2012) represents a downscaling technique, while the micro-canonical version (exact rainfall amount conservation for each time step, e.g. Olsson, 1998; Güntner et al., 2001; Licznar et al., 2011, 2015; Müller-Thomy et al., 2018; Müller-Thomy and Sikorska-Senoner, 2019) represents a disaggregation technique. However, for urban hydrology the majority of investigations with cascade models focus on the disaggregation of quasi-daily time series (with time step durations of 1280 min instead of 1440 min, e.g. Licznar et al., 2011, 2015; Molnar and Burlando, 2005; Paschalis et al., 2014) to achieve a final temporal resolution of 10 or 5 min. This enables use of the same branching number (that determines the number of finer time steps with equal duration resulting from one coarser time step) of b=2 throughout the disaggregation process with intermediate resolutions of {640, 320, 160, 80, 40, 20, 10, 5 min}. Since time series with 1280 min do not exist as observations, these studies are theoretical rather than practical from an engineering point of view. Of course, by the application of an additional transformation process a desired temporal resolution can be achieved, whereby the transformation process affects the characteristics of the disaggregated time series. To overcome this issue, Müller and Haberlandt (2018) developed a micro-canonical cascade model, which enables the rainfall disaggregation from daily values to 5 min. Müller and Haberlandt (2018) evaluated the disaggregated rainfall time series in terms of rainfall characteristics and showed good performances regarding continuous (average intensity, fraction of dry intervals) and event-based rainfall characteristics (wet and dry spell duration, wet spell amount) as well as extreme values. An additional validation with an urban hydrological model led to comparable results for event-based combined sewer overflow volume as well as manhole flooding volume when forced with observed and disaggregated rainfall time series, respectively.
Müller and Haberlandt (2018) also show that the autocorrelation of the disaggregated time series is underestimated. This is critical, because the autocorrelation describes the memory of a process. So for continuous applications especially, deviations can be expected whether e.g. an urban hydrological model is forced with observed or disaggregated rainfall time series. The underestimation of the autocorrelation in the generated time series has been identified before when micro-canonical cascade models were used for the disaggregation by e.g. Olsson (1998), Güntner et al. (2001) and Paschalis et al. (2012, 2014). Lisniak et al. (2013) divided the study period into a calibration period and a validation period. While for the calibration period the autocorrelation was underestimated, a good representation was achieved for the validation period. Rupp et al. (2009) and Pohle et al. (2018) analysed four and three different kinds of cascade models, respectively. Depending on the choice of the model, underestimations and overestimations of the autocorrelation function were identified. A good representation of the lag-1 autocorrelation was achieved by Hingray and Ben Haha (2005) with two micro-canonical cascade models. However, since only four disaggregation steps were applied (from hourly to 7.5 min time steps), it remains unclear whether the good representation would have been achieved for more disaggregation steps.
Summarising the previous findings, an adequate reproduction of the autocorrelation function by the multiplicative micro-canonical cascade model can be difficult. The reasons for overestimation and underestimation differ depending on the choice of the cascade model. For example, in Olsson (1998) and Müller and Haberlandt (2018) the underestimation is caused by the generation of dry time steps inside rainfall events, causing shorter wet spells in the disaggregated time series in comparison with the observed time series. In Pohle et al. (2018) an overestimation of the autocorrelation is identified for a cascade based on Menabde and Sivapalan (2000), which disables the generation of dry finer time steps from one wet coarser time step.
In this study, I investigate modifications of the cascade model itself, but also a post-processing strategy after the disaggregation procedure to improve the representation of the autocorrelation in the disaggregated time series. The basis for all investigations in this study is the multiplicative random cascade model as proposed by Müller and Haberlandt (2018). According to Marshak et al. (1994) it is a bounded cascade model with a single parameter set for each disaggregation level. The parameters are estimated by the aggregation of observed, high-resolution time series (Carsteanu and Foufoula-Georgiou, 1996). The modifications are based on the introduction of position dependencies with two different degrees of complexity. The first, less complex modification includes taking into account the position of the wet day in the time series. The second, more complex modification follows an idea of Lombardo et al. (2012, 2017). Lombardo et al. analysed which time steps are most worth considering to generate highly correlated time series under the burden of computational efforts. Their conclusion is adapted in this investigation. Both modifications are expected to improve the autocorrelation function and lead with the basis model to three different cascade model variants in this study. It should be pointed out that Lombardo et al. (2012) showed that the disaggregation process of discrete multiplicative random cascade models is non-stationary, “because the autocorrelation structure depends on the position in time in an undesirable manner”. Since the aim of this study is to improve the overall representation of the autocorrelation function (as an average over time), the extent to which the non-stationarity issue is solved by the introduced methods is not analysed.
Simultaneously, a second general issue of the cascade model is solved: the generation of time steps with very small rainfall intensities. Molnar and Burlando (2005) identified a fraction of rainfall intensities lower than the measurement resolution of the investigated time series of 48 % for 10 min time series, starting with the disaggregation from quasi-daily values. Müller and Haberlandt (2015) found for a disaggregation from daily to hourly values a fraction of underestimated rainfall intensities of 35 %. Koutsoyiannis et al. (2003) argue that it is unclear whether the values generated by the cascade model are too small in comparison to the observed minimum intensities or whether the resolution of the measurement device is not fine enough to observe the very small rainfall intensities generated by the cascade model. From a practical point of view, these low-intensity time steps are not important, but they have an impact on the autocorrelation function. To enable comparisons between the autocorrelation of observed and disaggregated rainfall time series a novel method is applied in this study to ensure a minimum rainfall intensity in the disaggregated time series.
In addition to the modifications of the cascade model itself, a resampling algorithm as a post-processing strategy is analysed to improve the autocorrelation. A similar approach has been investigated by Bárdossy (1998), who used a simulated annealing algorithm to resample time series generated with a Markov chain Monte Carlo method. Bárdossy (1998) investigated temporal resolutions of 1 h and 5 min; the autocorrelation function could be reproduced well for both. For this investigation, the proposed resampling algorithm of Müller and Haberlandt (2015) will be modified to include the autocorrelation function in the optimisation process.
As a summary from the introduction, the main research question of this study is, “How can the autocorrelation in the disaggregated time series be improved?”.
In this study, 24 stations in and around Lower Saxony, Northern Germany, are used (see Fig. 1). The same data set has been used before by e.g. Callau and Haberlandt (2017) for rainfall generation.
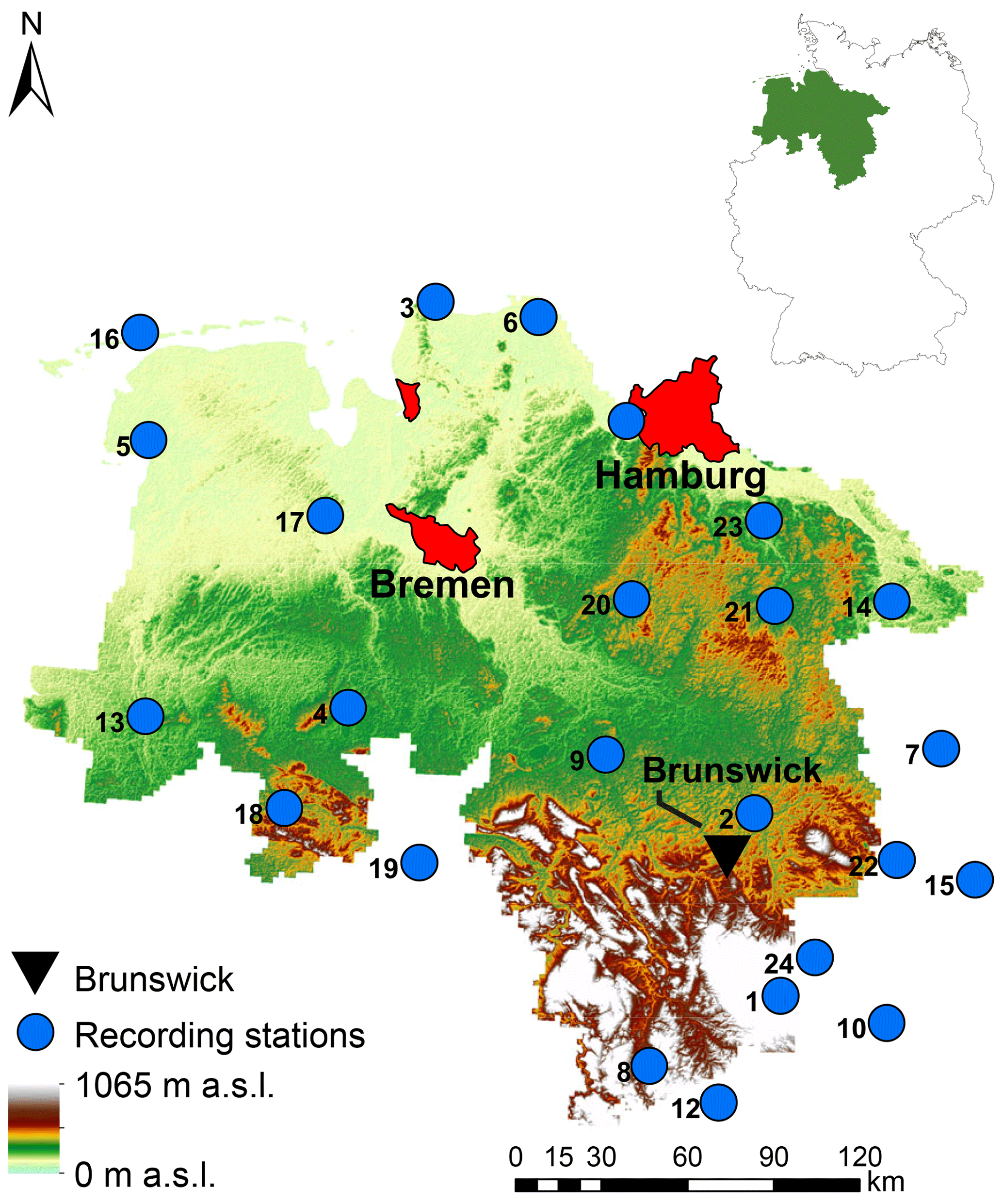
Figure 1Study area of Lower Saxony (and its location in Germany) with 24 recording stations and the cities of Hamburg, Bremen and Brunswick for orientation (based on the digital elevation model of the Shuttle Radar Topography Mission – Jarvis et al., 2008).
There are three dominating topographical regions with a coastal area around the North Sea, followed by the flatland around the Lüneburger Heide and the Harz middle mountains with altitudes up to 1141 m a.s.l. (from north to south).
Due to the climate classification following Köppen–Geiger (Peel et al., 2007), the study area can be divided into a temperate climate in the north and a cold climate in the mountainous region. Both climates exhibit no dry seasons, but hot summers. For the Harz mountains, average annual precipitation amounts greater than 1400 mm can be identified.
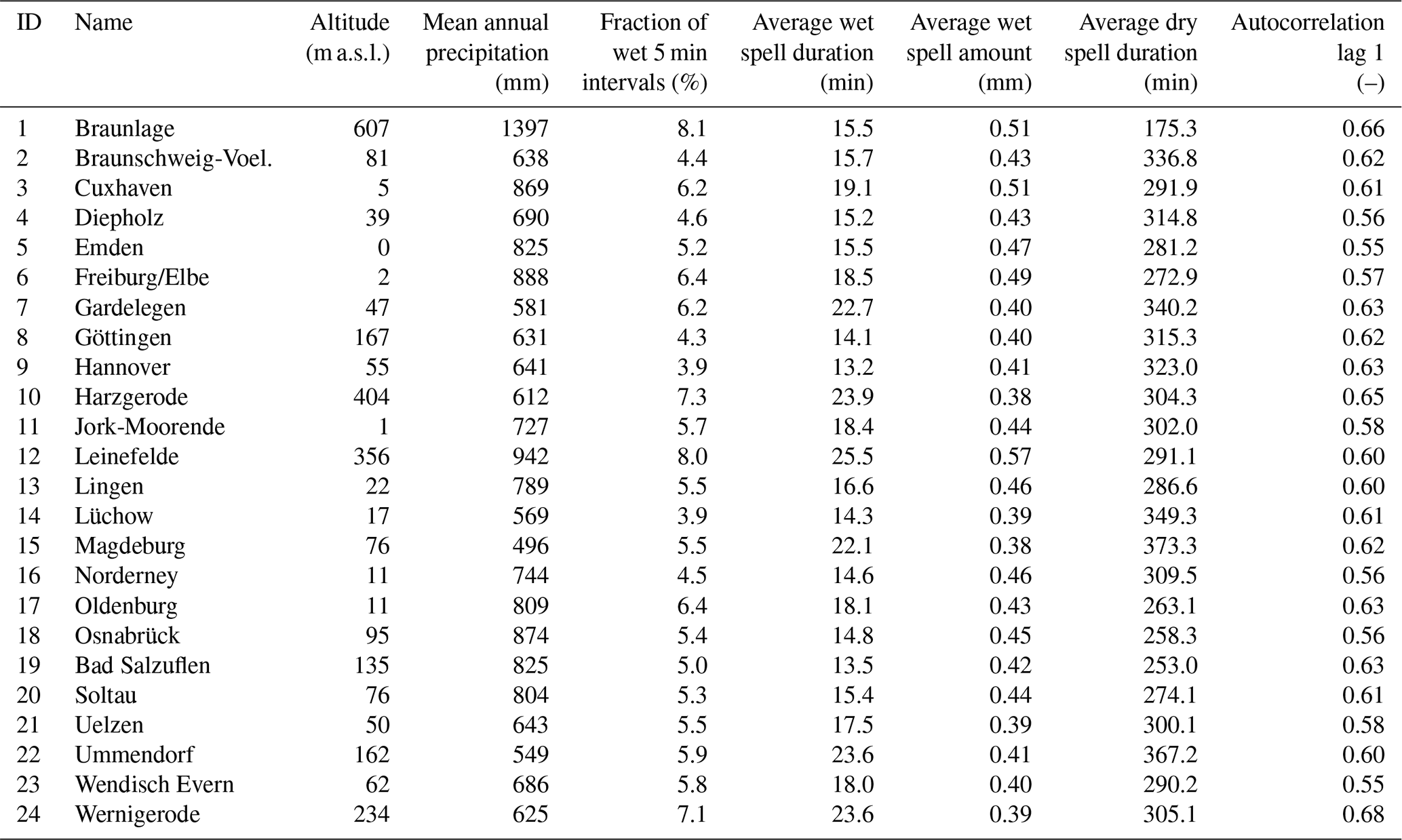
In Fig. 1, the 24 recording stations operated by the German Weather Service (DWD) with long term time series ranging from 9 to 20 years and a temporal resolution of 5 min are shown. The validation of the cascade model modifications is based on these 24 stations with a focus on the autocorrelation, but also on overall characteristics (average intensity, fraction of dry time steps), event characteristics (dry spell duration, wet spell duration, wet spell amount) as well as extreme values. The definition for a single event is according to Dunkerley (2008); having a minimum of one dry time step before and after the rainfall occurrence. For the definition of a dry time step the accuracy of the measuring instrument is not applied here, instead a threshold of zero rainfall is used. This enables comparisons between observed and disaggregated time series, since also smaller values resulting from the disaggregation process are included (see e.g. Molnar and Burlando, 2005). The rainfall time series characteristics along with further information of the rain gauges are provided in Table 1.
Table 1Attributes of all 24 rainfall stations, based on a temporal resolution of 5 min.
The overall aim of this study is the improvement of the autocorrelation rt1,t2 of the disaggregated time series with a temporal resolution of 5 min. The autocorrelation function (Eq. 1) describes the memory of a process (here: rainfall) by the comparison of time series with itself in the future (shifted time series), whereby the future is represented by a certain number of λ future time steps in the time series (lags). For rainfall time series Pearson's autocorrelation and Spearman's rank autocorrelation are applied in the literature (e.g. Pohle et al., 2018). Using Pearson's autocorrelation has two advantages: (i) it enables comparisons with results from the literature, since it is applied more often than Spearman's rank autocorrelation, and (ii) in terms of the later introduced resampling as an optimisation algorithm (see Sect. 3.2), for Pearson's autocorrelation no rank analysis of the whole time series has to be performed, since it can be calculated straight forwardly from the absolute values of the time series, which essentially quickens the optimisation. Hence, Pearson's autocorrelation is applied throughout this study.
The autocorrelation function is based on two elements: the covariance st1,t2 of the original and the shifted time series (t1 and t2, shifted by the lag λ with ), which describes the relation of both time series, and the standard deviations of both time series, st1 and st2, for the standardisation of the covariance. While t1 consists of n time steps, the rainfall amount at a single time step i is represented by x.
To improve the autocorrelation of the disaggregated time series, several methods are introduced. A flowchart of the methods is presented in Fig. 2. The method chapter is divided into three subsections, which will be briefly described. Section 3.1 includes the model description of the cascade model and two modifications to improve the representation of the autocorrelation in the disaggregated time series. These three cascade model variants are compared at the end of Sect. 3.1. In Sect. 3.2 a resampling algorithm to increase autocorrelation as a post-processing strategy after the disaggregation process is explained. The evaluation strategy for the disaggregated time series based on rainfall characteristics is explained in Sect. 3.3.

Figure 2Overview of applied methods (dashed rectangles) and the resulting data sets (bottom line). In the brackets behind the applied methods the subsection with the method description is referenced. Std refers to “standard” (no modification of the disaggregated time series), MMD is the “mimicry of the measurement device” to avoid too small rainfall intensities, and res refers to “resampled” time series.
3.1 Disaggregation model
3.1.1 General scheme (method A)
The principle of the micro-canonical, bounded cascade model applied in this study is illustrated for the first two disaggregation steps in Fig. 3 (top) and was introduced by Müller and Haberlandt (2018). A coarse time step is disaggregated into b finer time steps, with b named the branching number.
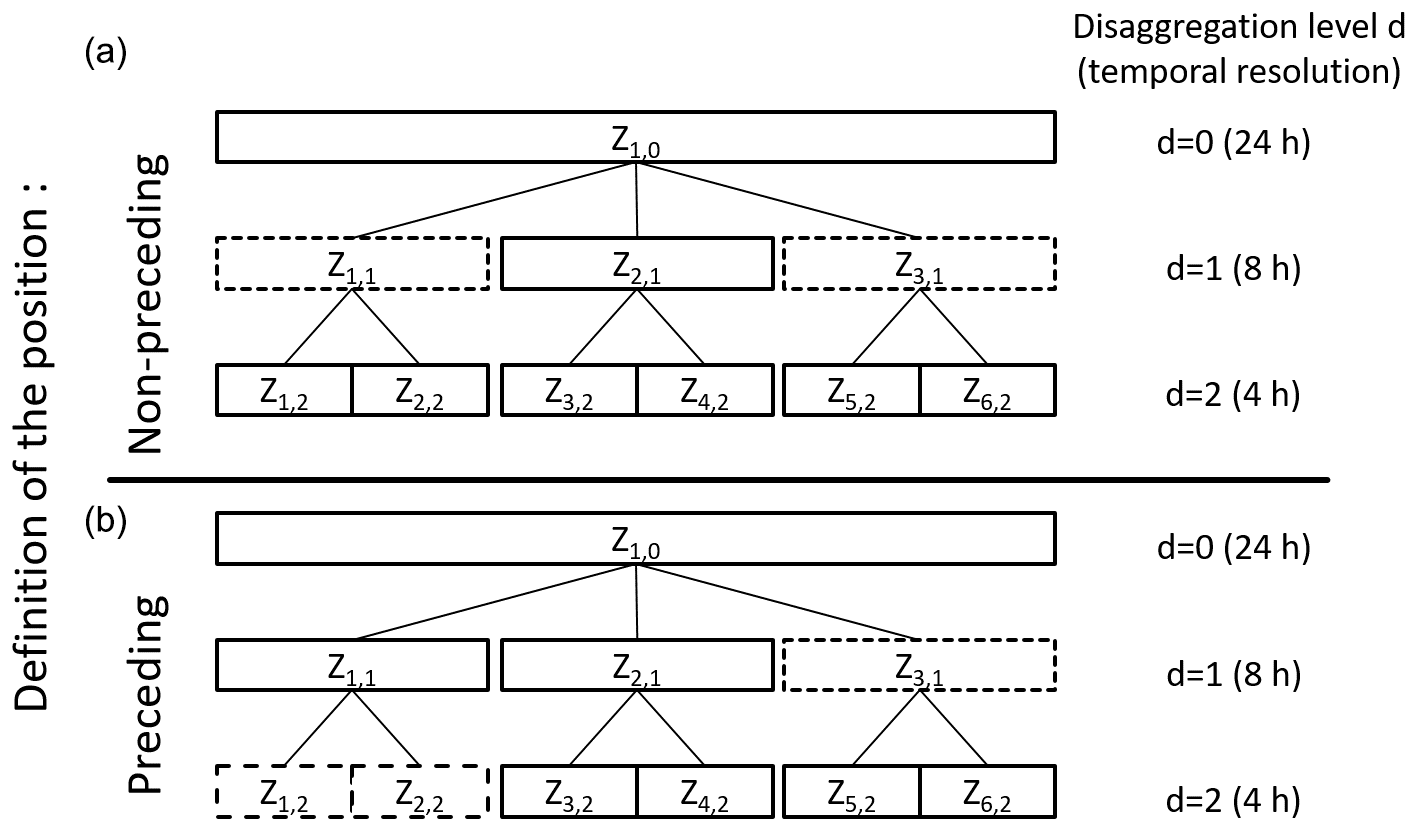
Figure 3Scheme for position definition in non-preceding (a) and preceding (b) cascade models. The dashed boxes indicate the time steps taken into account for position definition of the time step Z2,1.
Starting with daily values, b=3 is applied and three time steps with 8 h duration are generated (similar to Lisniak et al., 2013). The choice of b=3 in the first disaggregation step has no physical reason and is only applied to achieve with b=2 in the subsequent disaggregation steps a final temporal resolution of 5 min (see Sect. 1). The daily rainfall amount can occur in only one ( splitting), in two () or in all three of the finer time steps, whereby the rainfall amount is distributed uniformly on the wet time steps (as can be seen from the numbers in brackets that identify the fractions of the daily rainfall amount). The required parameters for this splitting are the probabilities P for one (), two and three wet 8 h intervals in a day. The parameters and ) have no influence on the position of the wet boxes, only on the number. The position is assigned randomly. The probability of can be determined by . The possible splittings and the distribution of the daily rainfall amount on the finer time steps are summarised in the cascade generator for b=3 (see Eq. 2). By multiplying the rainfall volume V of the coarser time step by the so-called multiplicative weights W1, W2 and W3, the rainfall amounts of the finer time steps are derived. The sum of the weights is equal to 1 in each split, so the rainfall amount is conserved exactly throughout the disaggregation process.
Also, a volume dependency of the parameter was identified for b=3. Müller and Haberlandt (2015) have shown that for days with high rainfall amounts (above an empirical quantile q0.998) the probability of two and especially three wet 8 h time steps is much higher than for lower daily rainfall amounts. Without a consideration of this volume dependency of the parameters, the probability is too high that high daily rainfall amounts are put into one 8 h time step, which will lead to an overestimation of extreme rainfall values. Hence, parameters are estimated for a lower and an upper volume class, with the quantile q0.998 of all daily total rainfall amounts as the threshold (see Müller and Haberlandt, 2015, for more details).
After the first disaggregation step, only b=2 is applied. The generated intermediate time series have temporal resolutions of Δt={4 h, 2 h, 1 h, 30 min, 15 min, 7.5 min}. The rainfall amount of the coarser time step can be assigned either to the first (1∕0 splitting) or to the second (0∕1) finer time step only or to both finer time steps (). Again, all probabilities (P(0∕1), P(1∕0) and ) sum up to 1. For the splitting, the relative fraction of the rainfall volume that is assigned to the first of the two finer time steps is considered a random variable x with 0 < x < 1. An empirical distribution function is used to represent f(x), with a maximum of 14 equidistant bins (based on the number of available splittings; see Storm, 1988, p. 86). The cascade generator for b=2 is given in Eq. (3):
The parameters for the splitting with b=2 depend on both the position and the volume class of the current time step to disaggregate in the time series (see e.g. Olsson, 1998; Güntner et al., 2001). The position of a time step is defined by the wetness state of the surrounding time steps, so starting (time step before is dry, time step afterwards is wet, dry–wet–wet), enclosed, ending and isolated positions can be distinguished (see Fig. 4 for an illustration). For each position two volume classes are defined, whereby the lower and upper volume classes are separated by the mean rainfall volume of each position.
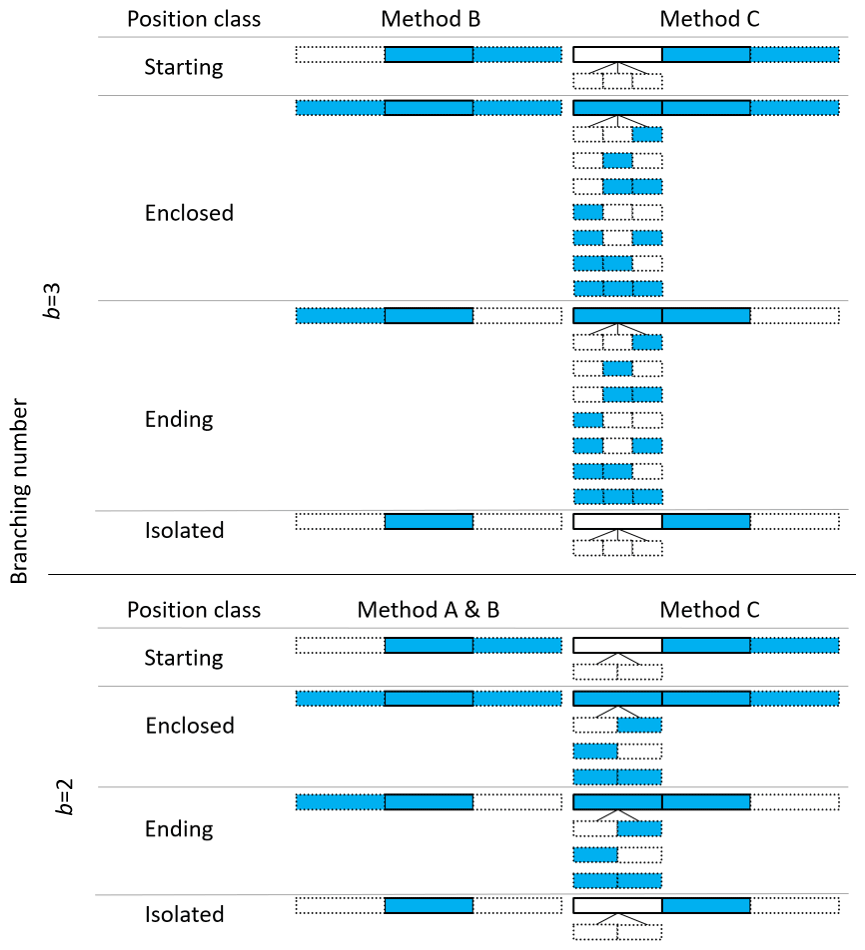
Figure 4Comparison of position classes definition for methods A, B and C. For method A, no position classes differentiation is applied for b=3. The dashed boxes indicate the time steps, which are analysed regarding their wetness state for the definition of the position class. Blue boxes indicate a wet time step, white boxes a dry time step.
All parameters for b=2 and b=3 splittings can be estimated by aggregating observed time series with the same temporal resolution (Carsteanu and Foufoula-Georgiou, 1996). As mentioned before, a bounded cascade model is applied (Marshak et al., 1994). In bounded cascade models the weights W depend on the temporal resolution to allow the disaggregation process to become smoother with finer resolutions (e.g. Menabde et al., 1997; Lombardo et al., 2012). The need for particular parameter sets for each temporal resolution arises from the wide temporal range (from daily to 5 min time steps) and hence the underlying processes, which differ between the temporal scales.
To summarise the previous explanation regarding parameter estimation: for each temporal scale two fine time steps are aggregated (or three finer time steps for b=3, respectively) to one coarser time step, whereby the position and the volume class of the coarser time step determines to which position–volume class combination the current splitting belongs. The cascade model parameters are then estimated over all splittings of a position–volume class combination, so all parameters and distribution functions included in the disaggregation process are estimated empirically.
A final temporal resolution of 5 min is achieved via uniform transformation (Müller and Haberlandt, 2018). The rainfall amounts of time steps with Δt=7.5 min are distributed uniformly on 2.5 min time steps and afterwards aggregated non-overlapping to Δt=5 min.
As mentioned in Sect. 1, the cascade model tends to generate too many time steps with too low intensities. To overcome the issue, rainfall amounts smaller than the minimum resolution of the measurement device are summated in the chronological order of the time steps until the sum Sthr exceeds this threshold. The former wet time steps with smaller intensities are set to 0 mm, while Sthr is moved to the last time step of the summation. Afterwards, Sthr is set back to 0 mm. This process is carried out over the whole disaggregated time series and is referred to as “mimicry of a measurement device” (MMD). If applied, Sthr is set to 0.01 mm in this study, which is identical to the minimum resolution of the measuring devices of the observed time series.
3.2 Introduction of position dependency in the uniform splitting (method B)
For method B, only the first disaggregation step (uniform splitting) is modified from method A in terms of the introduction of a position dependency. All further disaggregation steps remain identical to method A and are not changed.
For the disaggregation of daily values into 8 h, the cascade model is applied with a branching number of b=3. Although the number of wet 8 h intervals depends on estimated probabilities, their position is chosen randomly in method A. This is assumed to cause deviations of the autocorrelation.
Therefore, in addition to the volume classes, the position of the daily time step in the time series is also taken into account for the parameter estimation in method B. The same positions are applied for the further disaggregation steps with b=2 (starting, enclosed, ending and isolated positions; see also Fig. 4). For each position, the probability of possible placements of wet and dry 8 h intervals is estimated. The daily rainfall amount is split uniformly between the wet 8 h intervals. Based on the possible placements, the resulting cascade generator for the first disaggregation step is shown in Eq. (4) and substitutes for Eq. (2).
3.3 Introduction of a preceding cascade model (method C)
In the modification called the preceding cascade model, the position dependency for the whole disaggregation process is extended. Hence, the modifications for method C affect all disaggregation steps. Since only method C is referred to as a preceding cascade model, methods A and B can be considered non-preceding cascade models. Besides the modified position classes' definition, the disaggregation process remains identical to method A.
An example of the position-dependency extension is illustrated in Fig. 3 (bottom) and will be used for explanation. The indices f and g of each time step Zf,g represent an index for each time step (f=1, 2, …, n with n= length of the time series) and each disaggregation level (g=1, 2, …, 7), respectively.
For a time step Z (Z2,1) the wetness state of the time steps before (Z1,1) and afterwards (Z3,1) of the same disaggregation level are taken into account for the identification of the position so far (so-called “non-preceding” in Fig. 3). Hence, the type of splitting (1∕0, 0∕1 or ) is chosen independently from the wetness state of two already disaggregated time steps (Z1,2 and Z2,2) in the next disaggregation level. For the position definition in the preceding cascade model, the information about the wetness state of the two finer, already disaggregated time steps (Z1,2 and Z2,2) and the following, coarse time step (Z3,1) is taken into account (according to Lombardo et al., 2012, 2017).
Due to the new definition, the number of positions is extended from four in the non-preceding cascade model positions (starting, ending, enclosed, isolated) to eight in the preceding cascade model (see also Fig. 4): one starting ({0, 0}, 1,1 with 0= dry and 1= wet and { } indicating the wetness state of the preceding, already disaggregated time steps), three enclosed ({0, 1}, 1, 1; {1, 0}, 1, 1 and {1, 1}, 1, 1), three ending {0, 1}, 1, 0; {1, 0}, 1, 0 and {1, 1}, 1, 0) and one isolated position ({0, 0}, 1, 0) for b=2.
3.4 Comparison of cascade model variants
Due to the new introduced position definitions a comparative overview of the different position classes (Fig. 4) and the resulting number of cascade model parameters (Table 2) is provided. For the sake of comparability, the empirical distribution function used for the splitting for b=2 is considered simplified as an additional parameter, since the complexity of the disaggregation method is higher with f(x) than without. Nevertheless, it remains an empirical distribution function and is not a single parameter value.
Table 2Comparison of model parameters for methods A, B, and C in dependence of the applied branching number.
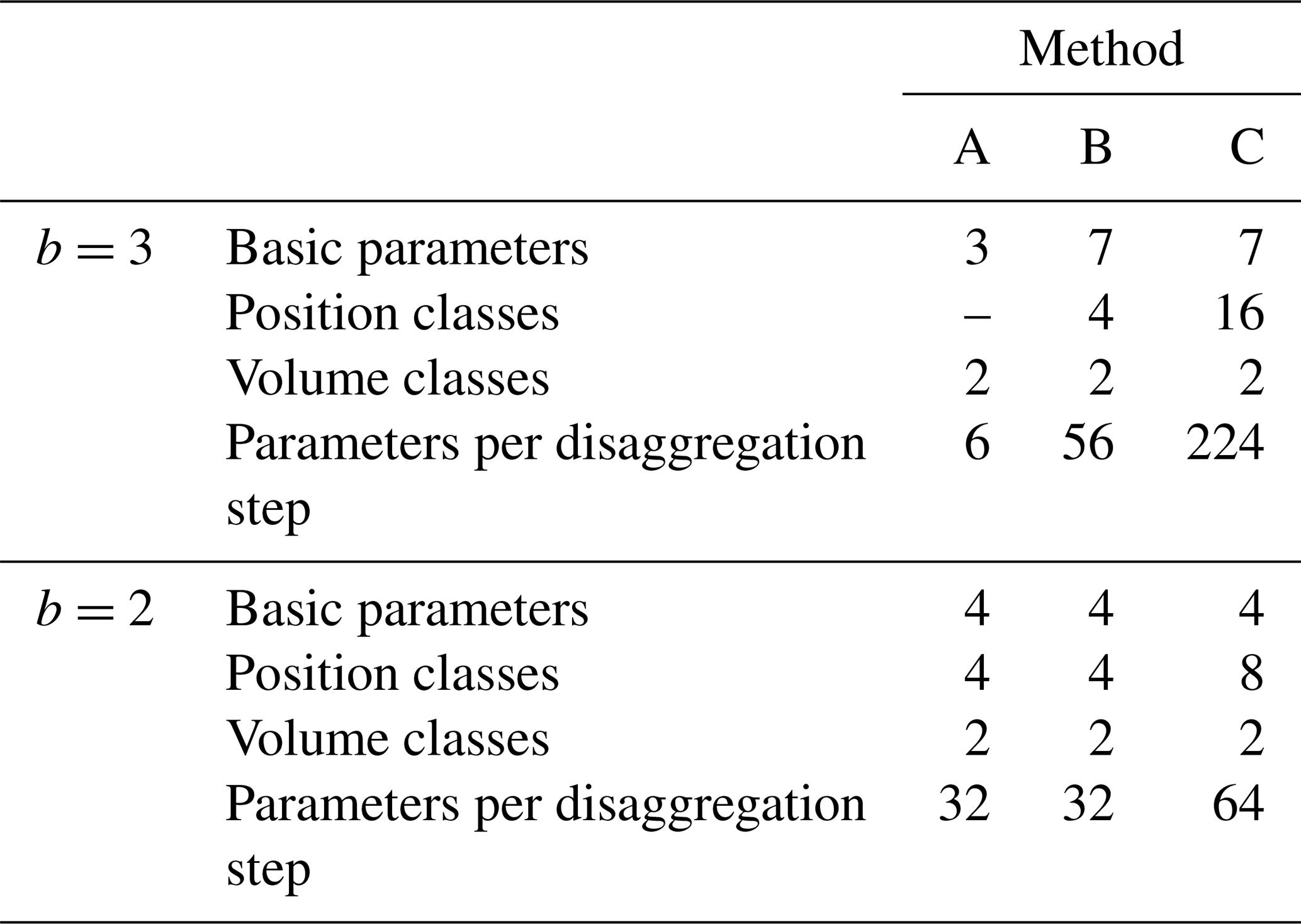
From Table 2 it is visible that the introduction of a position dependency for b=3 for cascade model B and the refinement of the position definition for cascade model C leads to an increase in cascade model parameters. Especially for method C the number of possible distributions of rainfall amounts in the already disaggregated time step before the current time step to disaggregate (see Fig. 4) leads to a strong increase in model parameters. Since all model parameters are estimated directly from observations, no parameter calibration is required and there is no problem with equifinality.
However, especially for the b=3 splitting for the upper volume class in method C, the number of parameters is critical. Since only days with rainfall amounts higher than the q0.998 quantile are taken into account, only a few days exist for the parameter estimation if the observed time series for parameter estimation is not long enough. This will lead to probabilities with P=0 for several splittings. While for some splittings P=0 seems reasonable from a physical interpretation (e.g. is reasonable, since the highest daily rainfall amounts have no dry spell in between with a minimum of 8 h in the observed data set), for other probabilities this can result from the too small population for parameter estimation. To ensure the applicability of method C in practice, a cross-validation is carried out (see Supplement).
3.5 Resampling algorithm
A different way to increase the autocorrelation is a post-processing resampling of the disaggregated time series, independent of the method used for disaggregation. In a resampling process, two elements (here: relative diurnal cycles of the disaggregated time series) are swapped to improve an objective function (here: minimising the deviation of the autocorrelation function of the disaggregated time series from the observed time series). In a relative diurnal cycle, the diurnal cycle with absolute rainfall amounts per time step is transformed by dividing the single rainfall amounts by the total rainfall amount of that day. With the simulated annealing algorithm as a resampling method it is possible to find the global optimum of an objective function. Simulated annealing has been used before for the optimisation of the autocorrelation of rainfall time series by Bárdossy (1998). However, these time series were simulated by a different rainfall generator. The resampling algorithm is applied with the following restrictions.
- a.
The structure of position and volume classes in the disaggregated time series generated by the cascade model should be conserved.
- b.
The daily rainfall amount should be conserved exactly.
For (a) the restriction is fulfilled by allowing only swaps of time series elements among subsets of the same position and volume class. Restriction (b) is fulfilled by swapping only relative diurnal cycles as time series elements, which does not affect the daily rainfall amount.
The objective function of the simulated annealing algorithm applied in this study is
The quantities indicated by * are the prescribed values for each lag from observed time series for each station, the other quantities are the current values. NoLags represents the number of lags analysed for the representation of the autocorrelation function. The number and selection of lags was carried out in a sensitivity analysis before by Föt (2015), resulting in 72 lags, whereby every second lag from lag 1 (5 min) to lag 144 (12 h) is taken into account (lag 1, lag 3, …, lag 143). After 12 h, the values of the autocorrelation of the observed time series show an asymptotic behaviour indicating a very low process memory. As proven by Müller and Haberlandt (2018), the resampling does not affect the scaling behaviour of the disaggregated time series (see Sect. 3.4), because the total rainfall amount as well as the number of wet time steps are kept.
In a prior study the effect of the resampling algorithm on the extreme rainfall values was analysed (Legler, 2017). Without taking the extreme values into account explicitly in the objective function, the resampling leads to a decrease in the extreme rainfall values over all scales. Since the extreme rainfall values are represented well after the disaggregation (Fig. 10), they would be underestimated after the resampling. Since the occurrence date and the magnitude of the extreme rainfall values differ among the investigated durations, for their identification an event-independent, general scheme has to be applied in order to take them into account in the objective function. The applied scheme is illustrated in Fig. 5. A threshold intensity Itr is chosen for the whole time series, whereby the first and last time steps of each day exceeding Itr determine the event and its duration Devent. During the resampling, swaps are only allowed if the following restrictions R are fulfilled.
- R I
-
The total rainfall amount of the extreme event must not decrease.
- R II
-
The number of dry time steps inside the extreme event must not decrease.
If Itr is chosen too high, extreme rainfall events of higher durations and most often lower intensities are not considered. If Itr is chosen too low, too many rainfall events are considered extreme events, which leads to a rejection of too many swaps during the resampling and hence only minor improvements of the autocorrelation function.
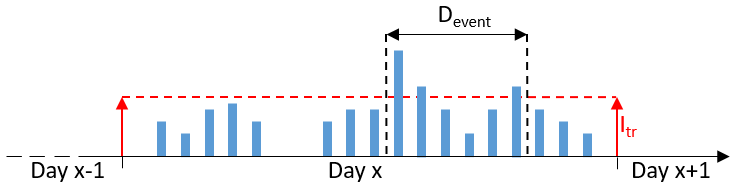
Hence, the choice of an appropriate Itr is essential for a successful resampling. Since it shall be possible to estimate Itr a priori without a calibration of this parameter, a transferable method was required. Müller and Haberlandt (2018) identified the existence of dry time steps inside extreme events of the disaggregated rainfall time series, while the observed extreme events consisted only of wet time steps. Since an event-based simulation of extreme rainfall events with D=30 min in an urban hydrological model led to satisfying results regarding flooding volume and combined sewer overflow volume in Müller and Haberlandt (2018), for the identification rainfall extreme events with D=60 min are considered in this study. For the observed time series of all stations, the average intensity of the extreme rainfall event with D=60 min and the empirical return period closest to Tn=1.5 years was calculated. It is assumed that the results regarding underestimation or overestimation for the return period Tn=1.5 years are representative of typical return periods for dimensioning purposes in urban hydrology (Tn={1, 2, 5, 10 years}, DWA-A 531, 2012). The resulting average intensity Itr=1.0 mm/5 min of the aforementioned extreme rainfall events is applied throughout the resampling and represents the 0.99 quantile for 25 % of all stations (ranging from ∼0.987 to ∼0.994 between all stations). Similar thresholds have been applied before in the literature for tracking of convective cells in radar images (Itr > 0.7 mm, Handwerker, 2002).
Since the number of diurnal cycles is limited in the disaggregated time series, the degree of improvement is limited as well, which can be a serious problem if only short daily rainfall time series are available. A possible solution is to enable the swapping of relative diurnal cycles between different realisations of disaggregated time series to increase the number of possible swap elements by additional realisations. Here the time series length was found to be sufficient and the resampling was carried out for each realisation separately.
The simulated annealing is carried out singular for each station as follows.
-
For each wet day the relative diurnal cycles are constructed. Subsets y for each applied position–volume class combination are created with .
-
A subset y is identified randomly. The probability of being identified is based on the number of elements m in the subset:
-
Two days are drawn randomly from the identified subset, their diurnal cycles are swapped. If R I and R II are not fulfilled, the swap is retracted and the algorithm proceeds with step 2.
-
Oauto (Eq. 5) is updated.
-
The updated value Oauto,new is compared with the former value Oauto,old. If , the objective function value has improved and the swap is accepted.
-
If , the swap is accepted with the probability π:
where Ta is the annealing temperature that controls the acceptance of bad swaps. Local optima can be left by the acceptance of bad swaps and the global optimum can be found. The decrease in the annealing temperature during the resampling (see step 8) leads to a lower probability of accepting non-improving swaps, enabling the identification of the global optimum.
-
Steps 2–6 are repeated K times.
-
Reduction of the annealing temperature:
-
After reducing the temperature, the algorithm proceeds to step 2.
-
Steps 7 and 8 are repeated until the algorithm converges, expressed by M swaps which do not lead to an improvement of Oauto higher than a certain threshold thr.
The following setup was chosen for the resampling: , dt=0.99, K= 500, M=200 and thr.
The different variants of the cascade model can be combined with the resampling approach for the improvement of the autocorrelation. A summary of the combinations and their abbreviations used throughout the paper are presented in Fig. 2.
3.6 Validation of the results
For the evaluation of the disaggregation process, the disaggregated rainfall time series are analysed regarding their scaling moments, different event-based and continuous rainfall characteristics and their extreme values. Since the cascade model is based on the scaling theory, it is proven if the disaggregated time series show the same scaling behaviour as the observations. Scaling behaviour is analysed with the relation
with moments M, moments order q, the moments scaling exponent K(q) and the scale ratio λ. The scale ratio represents a dimensionless ratio of two temporal resolutions of one time series. Dry time steps are neglected as well as time steps with rainfall intensities < 0.1 mm to reduce the impact of too small rainfall intensities and the transformation applied after the disaggregation to reach a final temporal resolution of 5 min. It is common to analyse the scaling behaviour with log–log plots of Mq and λ (Over and Gupta, 1994; Svensson et al., 1996; Burlando and Rosso, 1996; Serinaldi, 2010; Müller and Haberlandt, 2018). Moments are estimated as probability-weighted moments (Yu et al., 2014; Ding et al., 2015) due to their robustness against large rainfall intensities (Kumar et al., 1994; Hosking and Wallis, 1997). According to Kumar et al. (2014) and Lombardo et al. (2014) only the first three moments are analysed.
For an event-based evaluation, first the rainfall events are identified and then the characteristics of these events are determined. Event-based rainfall characteristics include wet and dry spell duration as well as wet spell amount.
For a continuous-based evaluation, the whole time series is considered, without differentiation into single events. As continuous time series characteristics, the average intensity, the fraction of dry intervals and the autocorrelation are analysed.
For the extreme rainfall event analyses, the event definition differs to ensure the independence of the extreme events. The definition depends on the extreme event duration under investigation. For extreme event durations shorter than 4 h, a minimum of 4 dry hours before and after the event ensure the independence of the event (Schilling, 1984). For longer extreme event durations, the same duration as under investigation has to be dry before and after the event. To increase the population of extreme events, partial duration series are extracted from the time series instead of annual maxima. Partial duration series are similar to the peak-over-threshold approach, whereby the threshold is defined in order to select three extreme rainfall events on average per year. Since the lengths of the time series of the analysed stations differ, theoretical distribution functions are fitted to enable comparisons for the same return periods among the stations. Following the DWA-A 531 (2012), which is a technical standard in Germany, an exponential distribution is fitted to the median of the realisations for each station.
To enable comparisons of rainfall characteristics at the same location, observed 5 min time series (Obs) are aggregated to daily values and then disaggregated back to 5 min time series (Dis). A split-sampling into calibration and validation periods was not carried out to keep the time series as long as possible for the parameter estimation (see also the discussion in Sect. 3.1.4).
The disaggregation is a random process. Depending on the choice of the random number generator initialisation different realisations are generated. This uncertainty is taken into account by performing 30 realisations for each station. By 30 realisations the random behaviour of the disaggregation process is fairly well covered. The mean and the range of the event-based and continuous rainfall characteristics were plotted against the number of realisations used for their estimation, and an asymptotic behaviour was identified with increasing numbers of realisations after 30 realisations.
For the validation the relative error rE and relative absolute error rAE are calculated to quantify the direction and amount of the deviation of the rainfall characteristic RC with i as a control variable of all realisations n:
4.1 Modifications to the cascade model
For an improved representation of the autocorrelation function, two modifications of the multiplicative cascade models following Müller and Haberlandt (2018) have been analysed, namely method B and method C. The resulting probabilities are shown for the uniform splitting in Table 3 (columns with position-dependent entries) in comparison to the position-independent probabilities estimated for method A (first probability column). For starting positions, splittings with wet 8 h intervals at the end of a day have the highest probabilities (for both one and two wet intervals). For ending positions, a vice versa relationship can be identified, with the highest probabilities of wet 8 h intervals at the beginning of a day. For enclosed positions, probabilities of a wet 8 h interval at the beginning or ending of the day, so with a temporal connection to another wet day, are higher if one interval is wet. All of these findings are similar to the findings from Olsson (1998) and Güntner et al. (2001) for a splitting with b=2. Also, independent of the position, it can be identified that probabilities for two connected wet intervals (1–1–0 and 0–1–1) are higher than the combination with an enclosed dry time step (1–0–1). The probability that three intervals are wet is highest for an enclosed position and lowest for an isolated position.
Table 3Position-dependent and position-independent probabilities for one, two and three wet 8 h intervals in the uniform splitting (mean of all 24 stations for the lower volume class, all values in percent – %). The combination of “1” (wet) and “0” (dry) illustrates the order of wet and dry 8 h intervals in a day.

The scaling behaviour of observed and disaggregated time series is shown in Fig. 6 for station Cuxhaven. The results are similar among the stations and the analysed moments. The disaggregated time series show an identical scaling behaviour down to a temporal resolution of 120 min. For finer resolutions slight overestimations occur for methods A and B and even slighter for method C. These deviations are presumably caused by fragments of the linear transformation applied after the disaggregation to achieve a final temporal resolution of 5 min. Overall, with a mean deviation of all three methods A–C from the observations of 0.08 for q=1 and a temporal resolution of 5 min, the scaling behaviour is represented well.
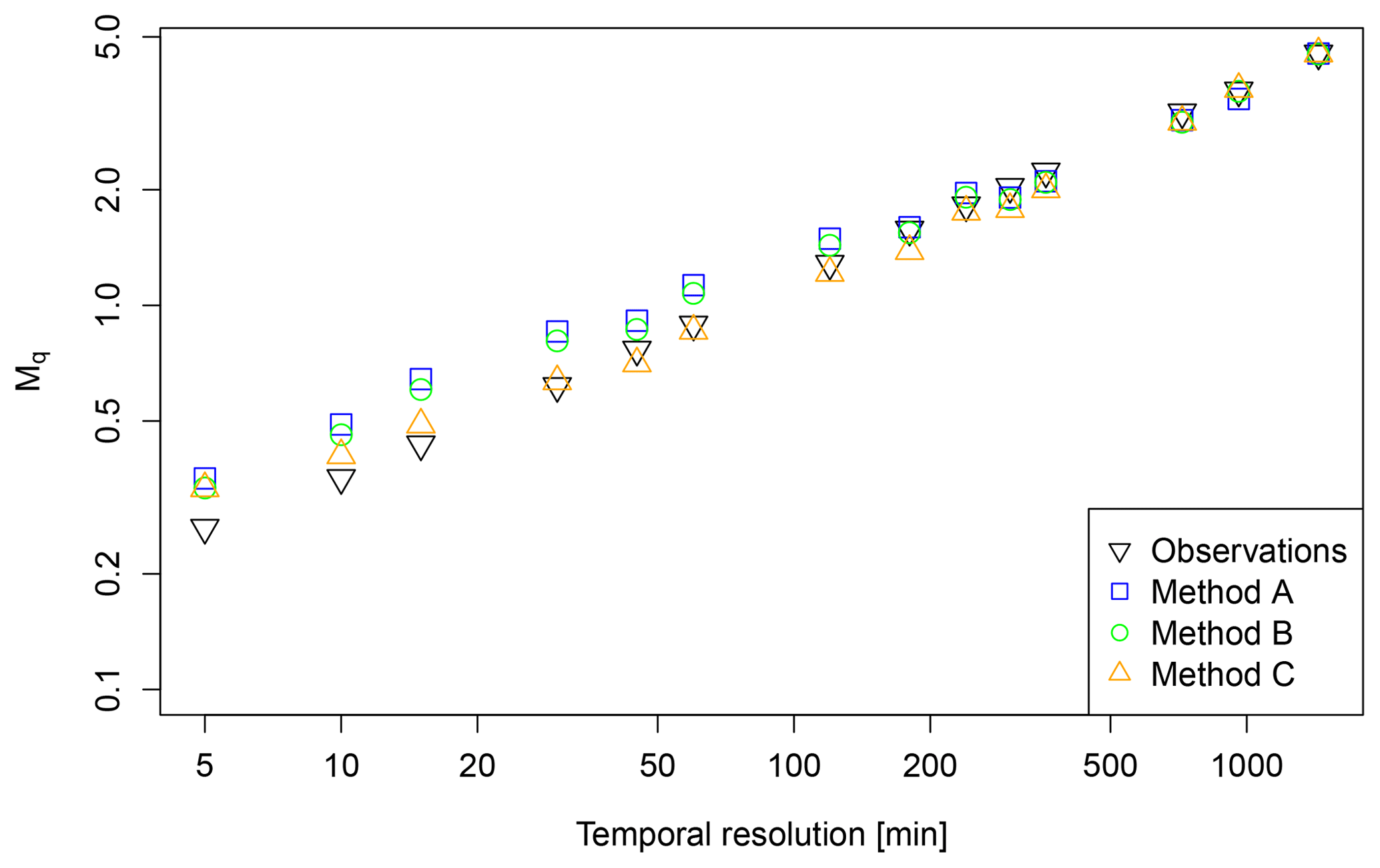
Figure 6Scaling behaviour of observed and disaggregated time series for station Cuxhaven for q=1. Each value represents the mean of 30 realisations.
The rainfall characteristics of the disaggregated time series are shown in Fig. 7 in comparison to observations. A quantitative analysis of the deviations is provided in Table 4 with relative rE and absolute errors rAE (see Eqs. 10 and 11) for the mean values of rainfall characteristics. Method A represents the original model proposed by Müller and Haberlandt (2018) and will be referred to as reference for the evaluation. Since the MMD approach is investigated for the first time, its influence on the rainfall characteristics of the disaggregated time series is analysed. If the too small rainfall intensities lower than the instrumental resolution of the measurement device are kept after the disaggregation (hence, MMD is not applied), the results are referred to as “A/B/C-standard”. If the too small rainfall intensities are eliminated by the MMD approach, the results are referred to as “A/B/C-MMD”.
Table 4Relative and absolute error of rainfall characteristics between disaggregated and observed time series (mean for 24 stations).

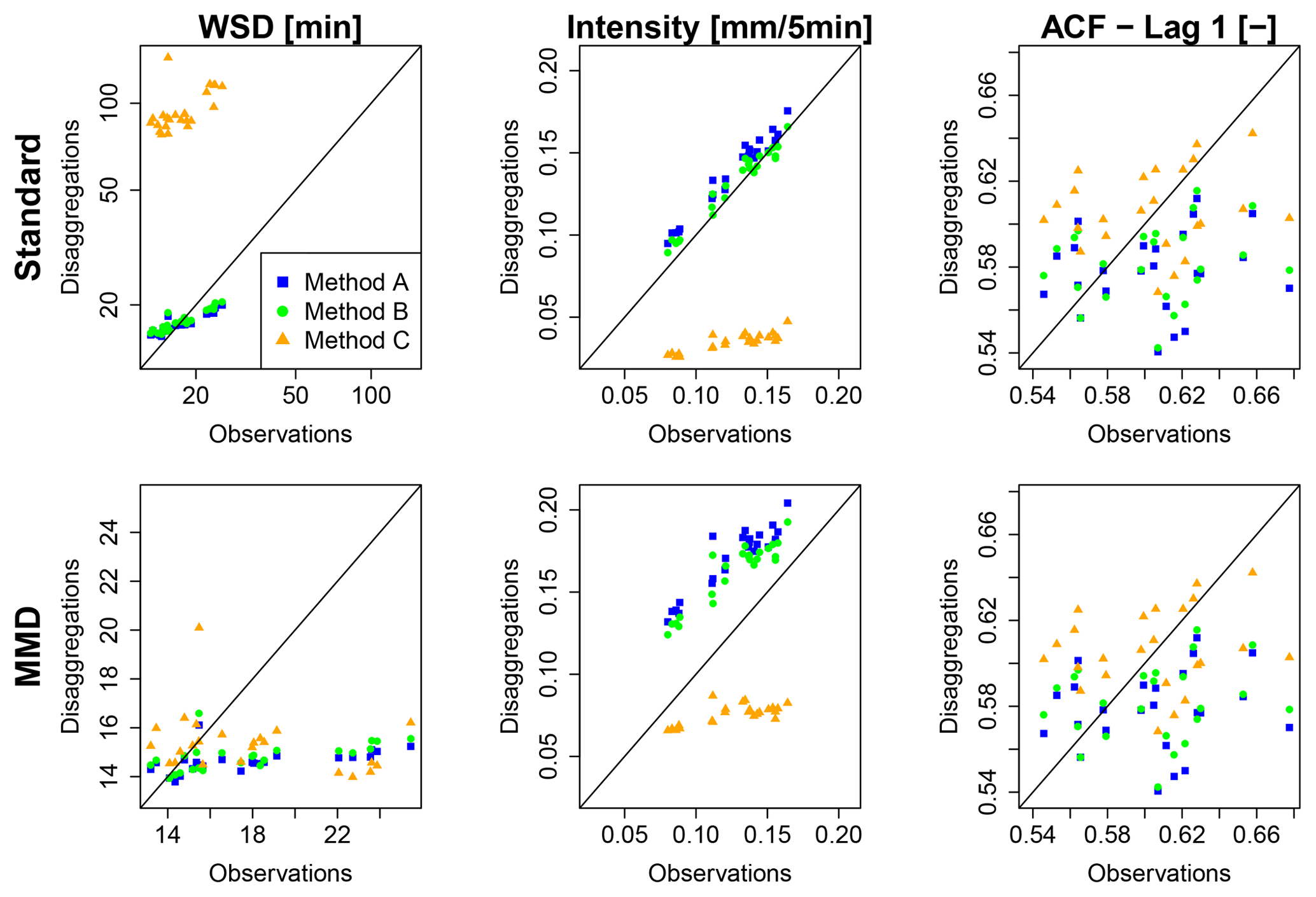
Figure 7Rainfall characteristics of observed and disaggregated time series as x-y plots for all 24 stations (WSD = wet spell duration, ACF = autocorrelation function; note the different scales for wet spell duration).
While for method A-standard a slight overestimation for the average intensity is identified (rE =11 %), for wet spell duration (−3 %) and amount (8 %), dry spell duration (8 %), fraction of dry intervals (1 %) and lag-1 autocorrelation (−4 %) a good representation is achieved.
With the introduction of a position dependence in the disaggregation step from daily values to 8 h values in method B-standard an improvement of all rainfall characteristics can be achieved. The improvements of the wet and dry spell durations are direct consequences of the better representation of the wetness state of 8 h intervals as is indicated by the parameter values in Table 3. For the average intensity with rE =3 % a major improvement from an overestimation of rE =11 % (A-standard) is identified.
For method C-standard, a worsening of the majority of rainfall characteristics is identified. Wet spell duration is overestimated with rE =399 %. This is caused by the high probability of splitting for enclosed boxes in the preceding cascade model, which decreases the probability of splitting one event into two events by the generation of dry time steps. This leads to a high number of wet time steps (underestimation of fraction of dry time steps rE %) and consequently to an underestimation of average rainfall intensities (rE %) due to the exact mass conservation of the cascade model.
Too small intensities can be avoided by the MMD approach. For methods A and B, the exclusion of small rainfall intensities leads to a worsening of rainfall characteristics (Fig. 8, Table 4). This indicates that the aforementioned good representation of rainfall characteristics by method A-standard and B-standard is biased by wet time steps with rainfall amounts lower than the observed minimums (depending on the instrumental resolution of the measurement device). Since time steps with these rainfall intensities are negligible from a hydrological point of view, the line of MMD in Fig. 7 provide a more useful insight into the disaggregated data.
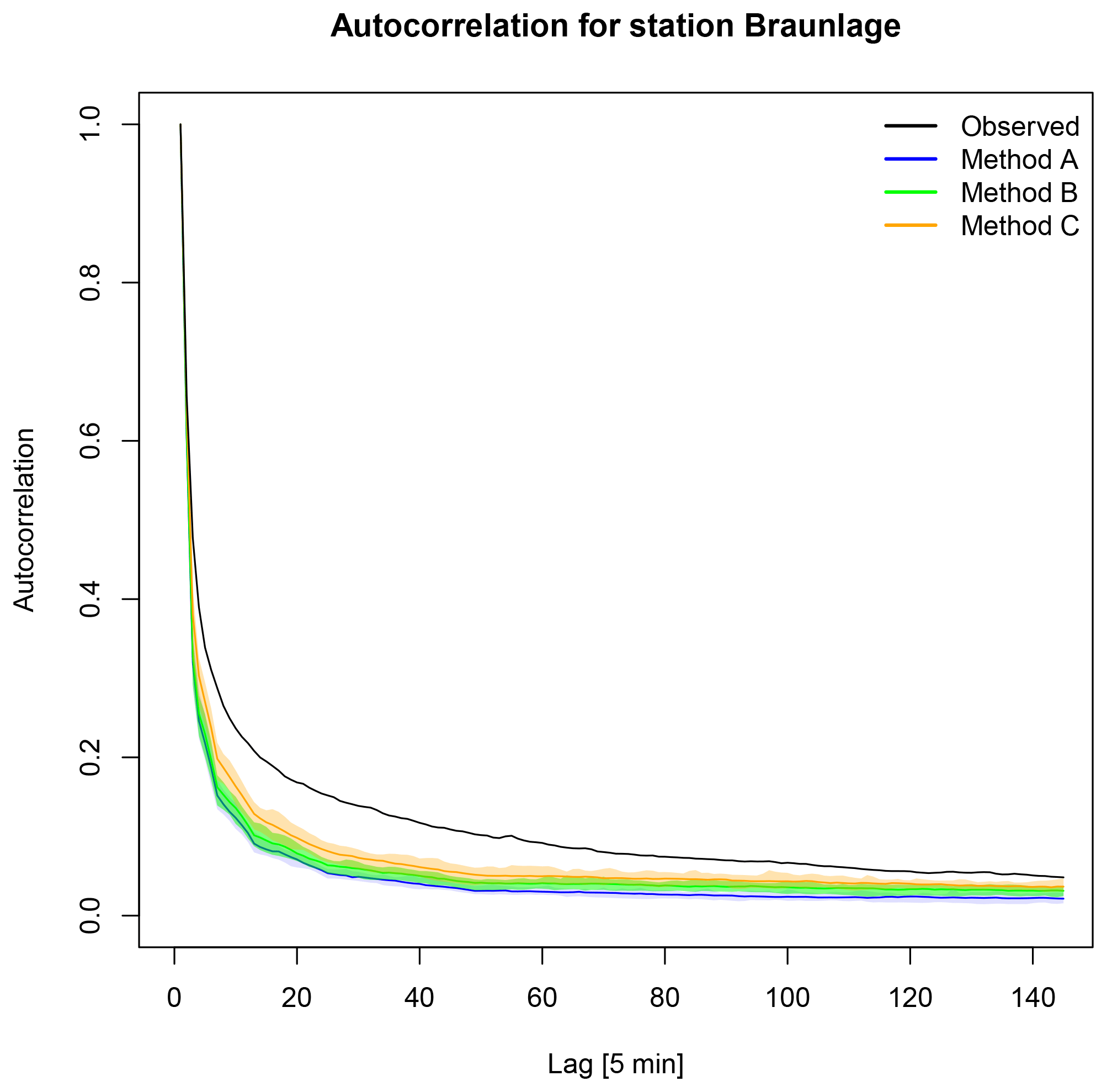
Figure 8Autocorrelation of observed and disaggregated time series using the standard approach for each method with no modification regarding too small rainfall intensities. The range for each method results from 30 realisations, and the solid line represents the median.
The overestimation of the average rainfall intensity by methods A and B increased to rEMMD=40 % and 32 %, respectively, while the underestimation by method C is reduced to rE %. An improvement for wet spell duration is also identified (rE %). Although the fraction of dry intervals improved with MMD (rE %), a worsening of the dry spell duration is identified (rE %), indicating a higher fraction of short dry spells inside former events on a coarser timescale.
Methods A and B result in similar values for wet spell durations to method C for MMD. For wet spell amount and duration, average intensity, dry spell duration and fraction of dry intervals a decrease in performance is identified by MMD in comparison to the standard approach.
Since the focus of this study is the improvement of the autocorrelation, the impact of MMD on methods A, B and C is investigated as well. From a visual inspection of the lag-1 autocorrelation in Fig. 7, a systematic underestimation as mentioned in Sect. 1 is not visible, since for some stations even overestimations occur. However, a comparison between observations and disaggregated time series resulting from different methods until lag 144 (representing a time shift of 720 min =12 h) shows differences and a clear underestimation by the disaggregation for station Braunlage (Fig. 8). For other stations the relationship is similar, although for some the differences between methods A and B are smaller. In Fig. 9 the relative error between the median of the autocorrelation function of all 30 realisations for each method and the observed time series is shown for all stations regarding lags 1 (5 min), 6 (30 min) and 36 (180 min). Independently of the applied methods, the deviation is increasing from lag 1 to lag 6, while for lag 36 the deviation has decreased. Also, the range of deviations is decreasing for an increasing number of lags. This is visually confirmed by the results for station Braunlage (Fig. 8), where the autocorrelation of the disaggregated time series decreases strongly with the first lags, while it decreases much more smoothly for the observed time series. The choice of the disaggregation method (methods A, B or C) has a higher impact on the resulting autocorrelation than the choice of treatment of the too small rainfall intensities (Standard or MMD). In fact, the MMD approach has only a slight effect on the autocorrelation function values. The smallest deviations of the autocorrelation function are achieved with method C, independently of the treatment of the too small rainfall intensities.
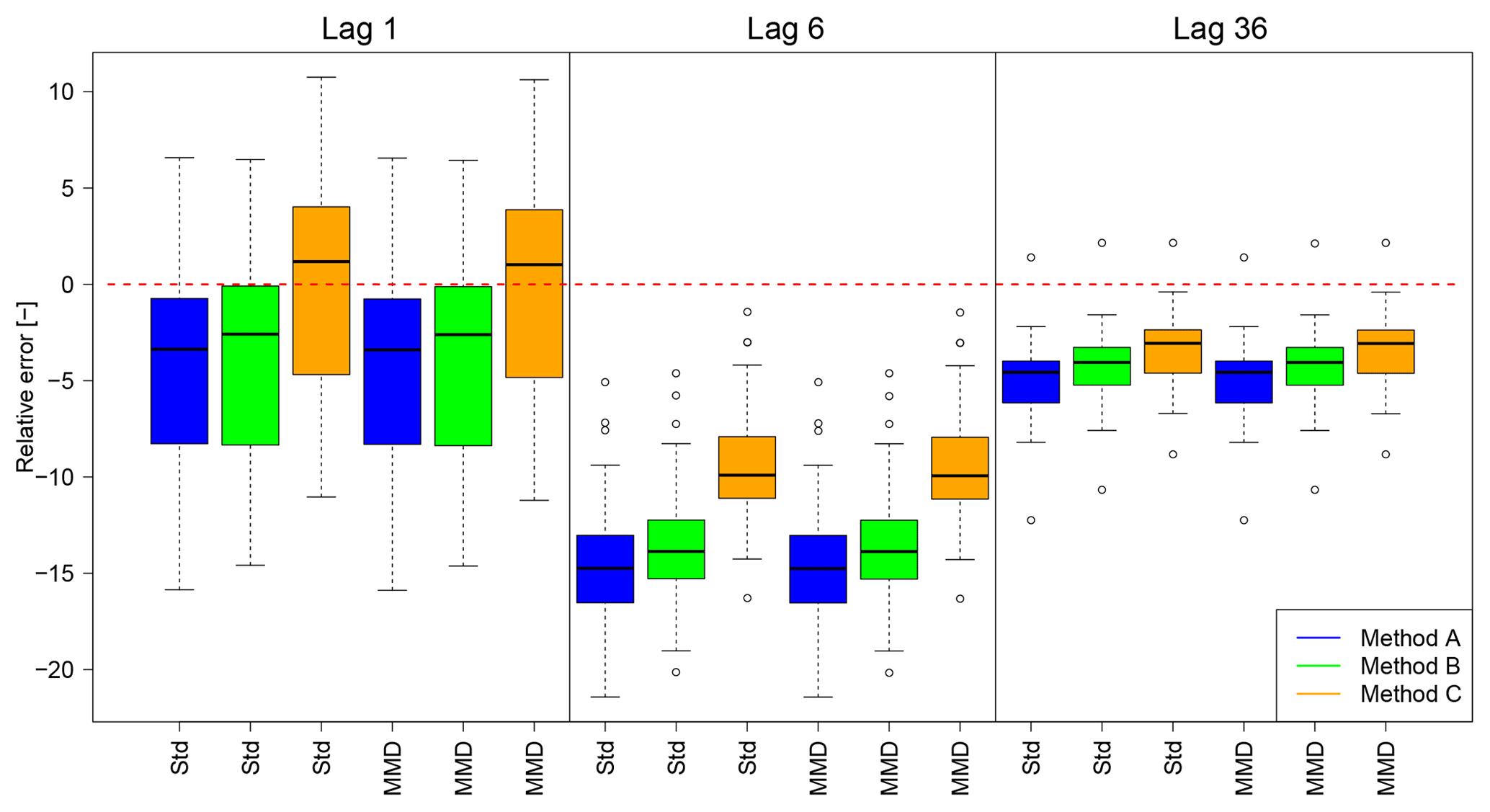
Figure 9Deviations of autocorrelation from disaggregated to observed time series as relative error for lags 1, 6 and 36. The red dashed line indicates a rE =0 (Std is used as abbreviation for Standard).
The results of the extreme rainfall value analysis are illustrated in Fig. 10 for two durations D (5 min and 1 h) and two return periods T (1 and 5 years). For the extreme events, only methods A, B and C are differentiated between. The modifications regarding the minimum rainfall intensity are not taken into account since they do not affect the rainfall extreme events.
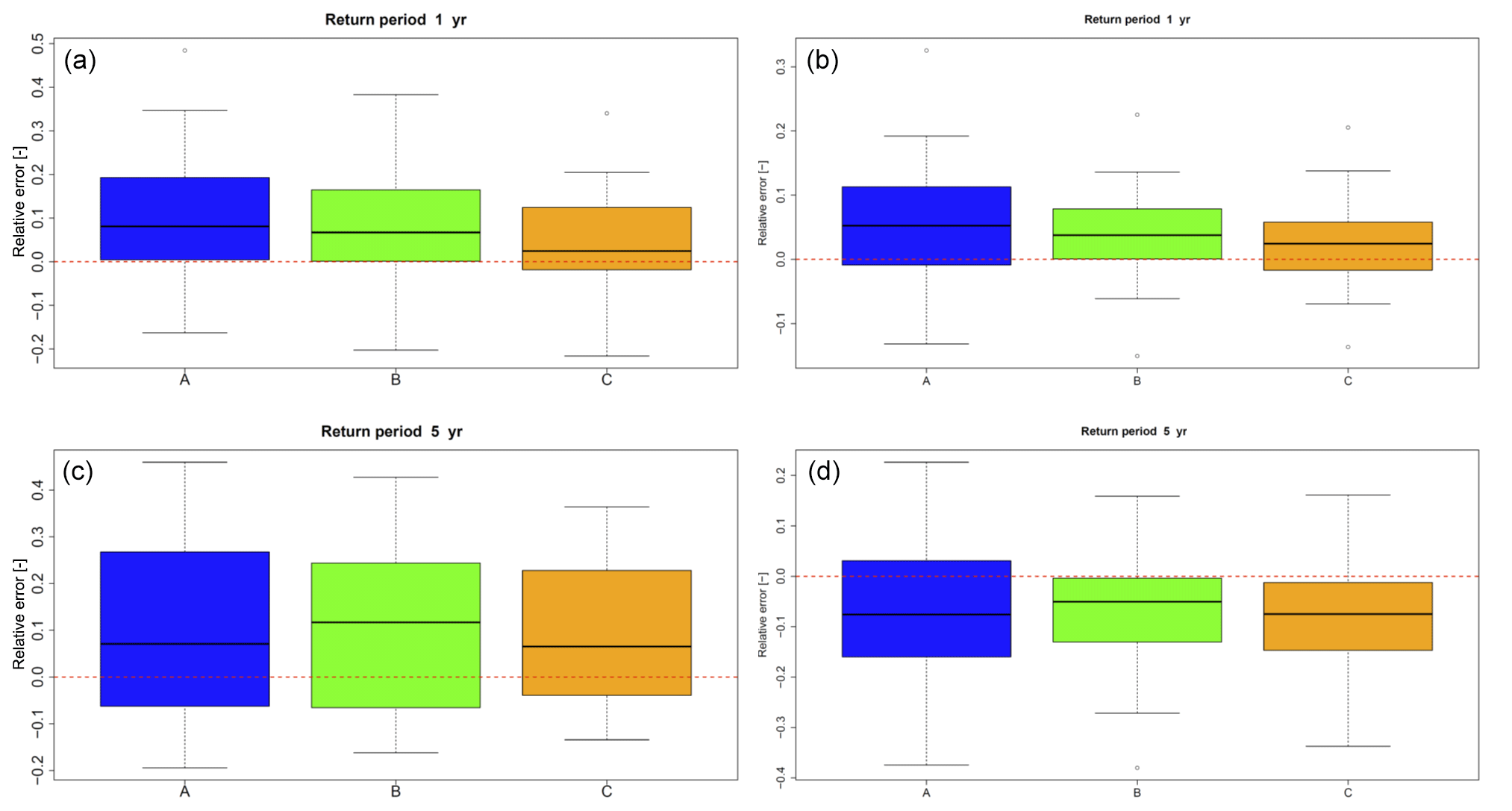
Figure 10Mean relative errors of extreme values of the disaggregated time series for all stations (the dashed line represents an error of 0). Results are shown for durations of 5 min (a, c) and 1 h (b, d) and for return periods of 1 year (a, b) and 5 years (c, d).
For a return period of 1 year extreme rainfall values are slightly overestimated by less than rE =10 % for the half of all stations and less than approximately rE =20 % for 75 % of all stations for both analysed durations, independent of the applied modification of the cascade model. For 5 years, the range of results is increasing, leading to a worse representation in comparison to 1 year. While for a temporal duration of D=5 min a slight overestimation of approximately rE =10 % for half of all stations can still be identified, for 1 h an underestimation of rE =50 % is identified for half of all stations. However, increasing deviations with increasing return periods can be expected, since for a few of the time series with lengths of only 9 years the return period is limited to T=3 years (1∕3 of time series length) to ensure plausibility from a hydrological point of view.
Nevertheless, it should be noted that over all return periods and durations, method C led to the smallest range of relative errors over all stations in combination with the best fit to the distribution of the observed extreme rainfall values. The cascade model parameter transferability in space was confirmed by a cross-validation for method C (see Supplement).
4.2 Resampling results
For the resampling, only disaggregated time series modified by the MMD approach are used due to their slightly better representation of the autocorrelation. The autocorrelations of the disaggregated time series before and after the resampling are shown in Fig. 11 for lag 1, lag 6 and lag 36. A general increase in the autocorrelation along with smaller deviations for the median of all stations compared to before the resampling can be identified for all three methods A, B and C. Only for the lag-1 autocorrelation of the rainfall time series disaggregated with method C does the resampling lead to a worsening regarding the median value. However, the range of the lag-1 autocorrelation results is reduced, indicating that the underestimations and overestimations were reduced by the resampling approach.
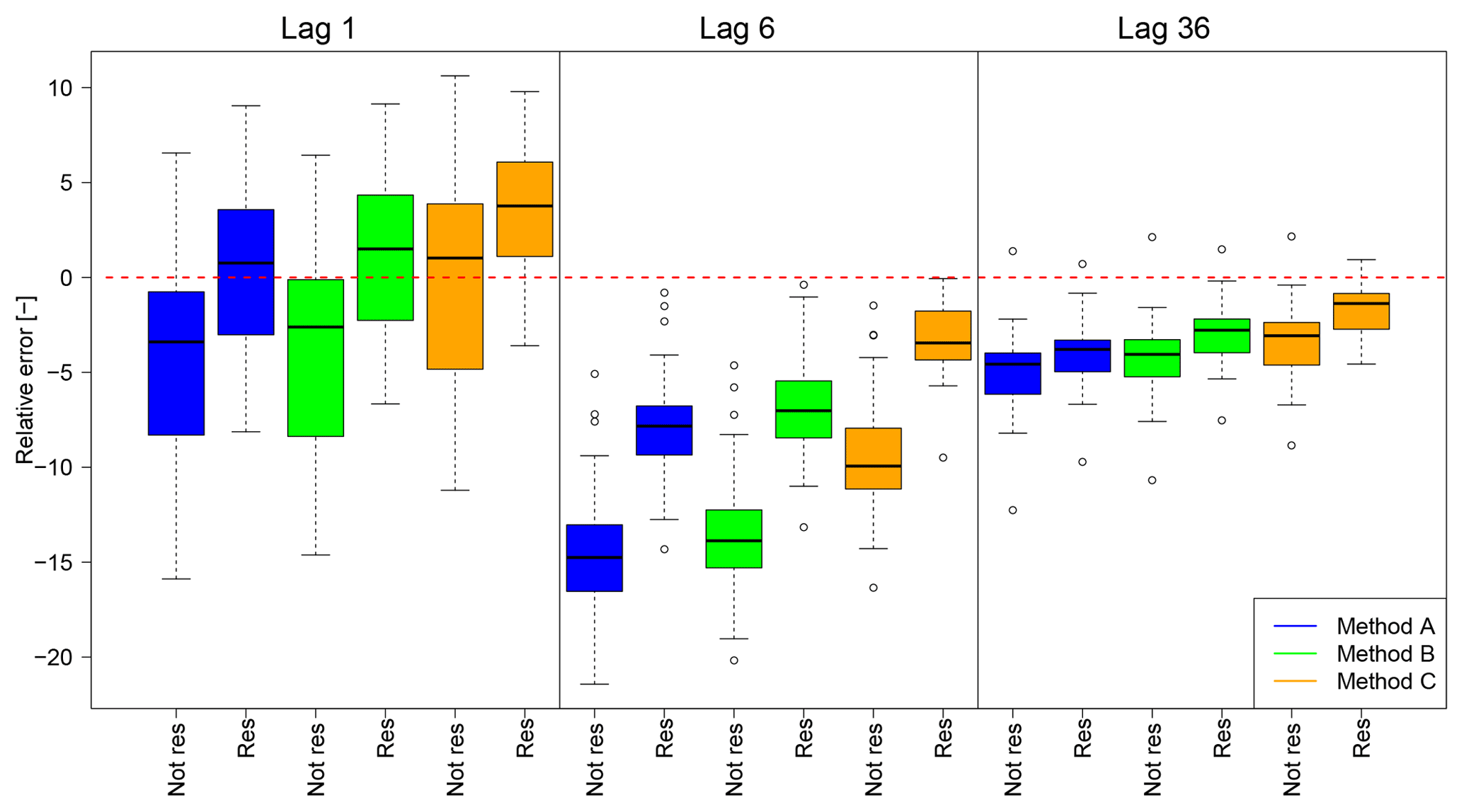
Figure 11Deviations of autocorrelation from disaggregated to observed time series before and after the resampling as relative error for lags 1, 6 and 36. All results are based on the MMD approach. The red dashed line indicates a rE =0, results for the resampled time series are labelled with “res”.
As mentioned before, the improvement of the autocorrelation depends on the chosen threshold for extreme rainfall value definition, Itr. An increase in Itr leads to a decrease in the number of rejected swaps during the resampling, since fewer time steps are involved in the extreme value analysis. An unrealistically high value of Itr (identical to leaving out both restrictions R I and R II regarding extreme rainfall values) leads to almost perfect fits for lag 1 and lag 36 (|rE| < 1 % for the majority of the stations), and for lag 6 deviations of up to |rE| < 3.5 % occur (not shown here). However, the extreme rainfall values are underestimated strongly if Itr is chosen too high.
Hence, both restrictions R I and R II are applied during the resampling by the choice of Itr=1 mm. In Fig. 12, the extreme rainfall event series for station Osnabrück is shown for D=5 min. Although the extreme event series changed slightly after the resampling, the overall extreme series characteristics regarding range, underestimation and overestimation in comparison to the observations remain the same for all return periods.
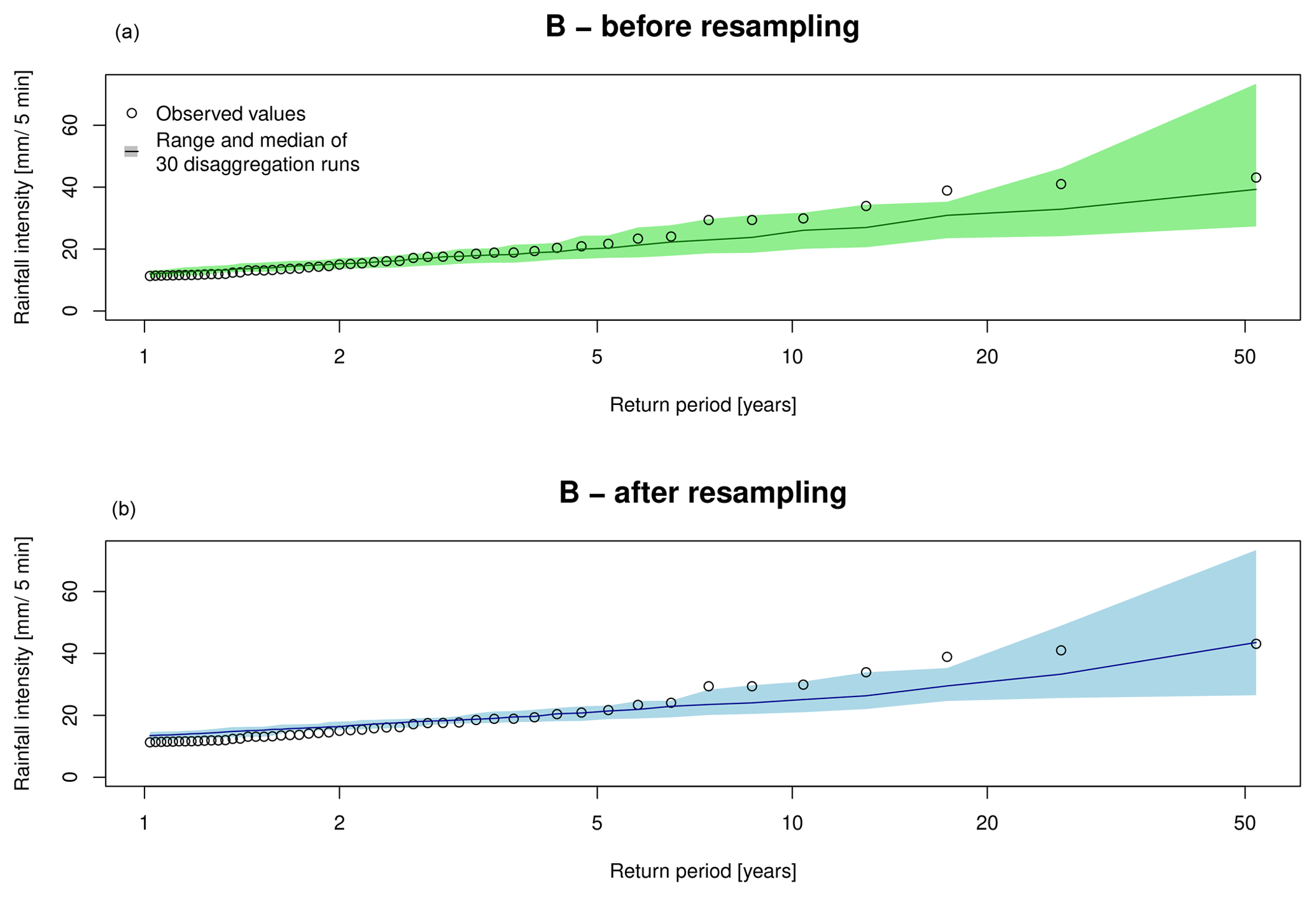
Figure 12Extreme rainfall values for D=5 min for station Osnabrück based on 30 disaggregation realisations with method B before (a) and after (b) the resampling.
For extreme rainfall events with longer durations (D={15 min, 1 h, 2 h}) the impact of the resampling is quantified in Table 5. The impact of the resampling depends on the analysed duration of the extreme rainfall events. While for D=15 min the median of rE has decreased after the resampling with smaller |rE| for the smaller return periods (Tn={1, 2 years}) and higher |rE| for Tn=10 years, for D=2 h the median of rE has increased after the resampling with higher |rE| for the smaller return periods and smaller |rE| for Tn=10 years.
Table 5The median of rE of extreme rainfall events (over all stations and realisations) for different return periods and disaggregation methods before and after the resampling.
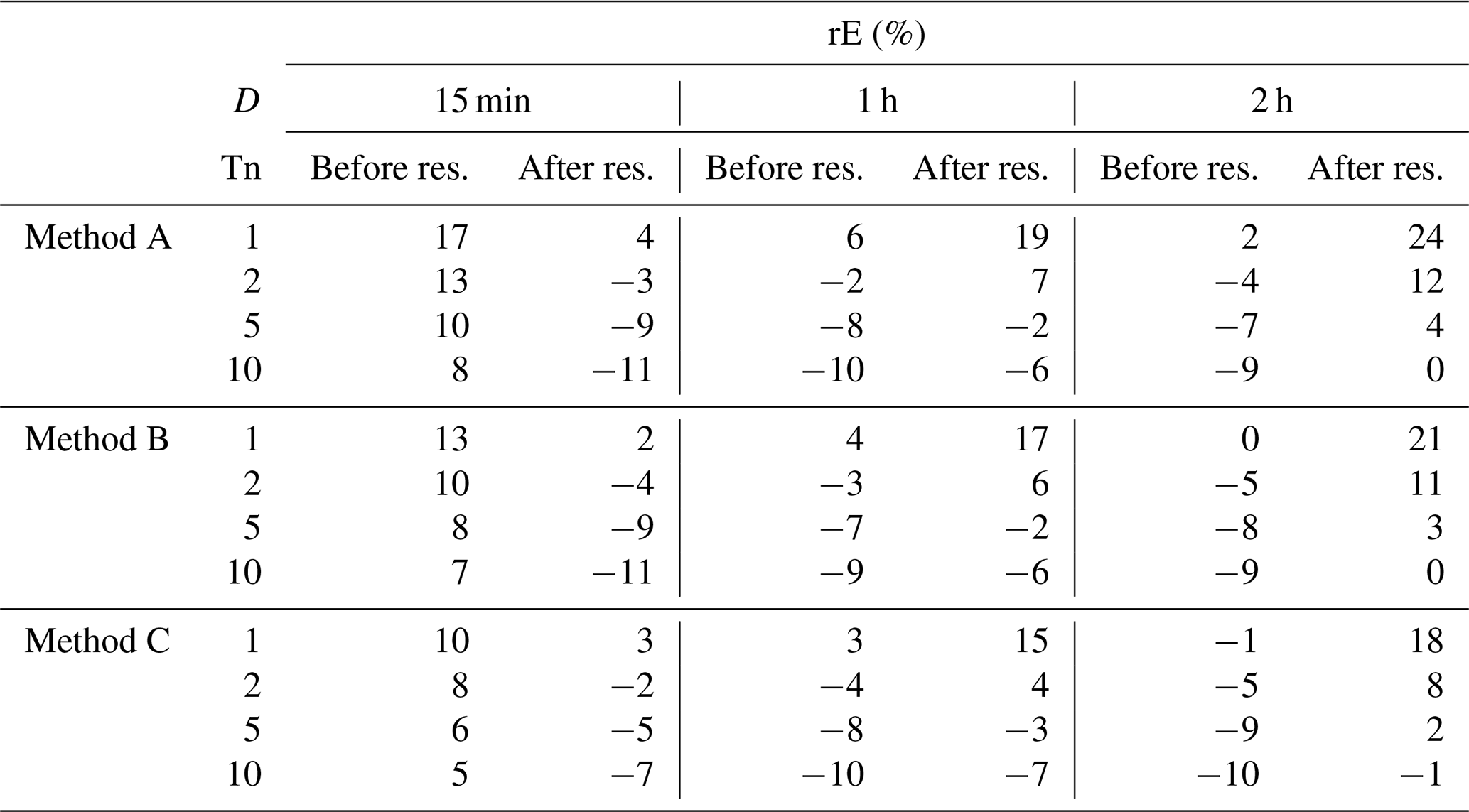
Since these findings are independent from the disaggregation method, the differences are caused only by the resampling. Extreme rainfall events with D=15 min represent convective events with only a few wet time steps preceding and succeeded by dry time steps. Due to the short event duration, the possibility of dry time steps in between is small and R I is the active restriction, which requires the total rainfall amount not to decrease, resulting in an increase. Extreme rainfall events with D=2 h originate from long-lasting, stratiform events with a high fraction of wet time steps in the current day. Since this fraction of wet time steps can also be found in the disaggregated time series, the rainfall amount will be distributed on more wet time steps to fulfil the active restriction R II to increase the autocorrelation.
However, the majority of rE values presented in Table 5 is smaller than 10 %, which indicates a good representation of the extreme rainfall events in the disaggregated time series in general, independent of the application of the resampling algorithm.
5.1 Impact of the cascade model modifications
The two new introduced micro-canonical cascade model variants methods B and C differ regarding their way of how the disaggregation process depends on a position of a wet time step in a rainfall time series and how it is defined. Both the position dependency in the first disaggregation step with b=3 for method B and the position definition following Lombardo et al. (2012, 2017) for method C are based on additional parameters of the disaggregation model (see Table 2). However, all new parameters are process-based and physically interpretable, since they describe the rainfall dependency of past time steps. Hence, an improvement of the autocorrelation, which describes the process memory, was expected. While method B differs from method A only in the first disaggregation step, a smaller improvement of the autocorrelation can be identified, while method C differs in every disaggregation step, and thus a higher improvement is identified.
To reduce the increase in the number of parameters by methods B and C, several possibilities exist. Olsson (1998), Güntner et al. (2001) and Müller and Haberlandt (2018) identified similarities between cascade model parameters of different position classes which can be used for simplification. These similarities are e.g. P(0∕1) for starting and P(1∕0) for ending positions (and vice versa) as well as P(0∕1) and P(1∕0) for both enclosed positions and isolated positions. Another possibility is to apply a semi-bounded cascade model instead of a bounded cascade model. While in a bounded cascade model for each step of the disaggregation process the corresponding parameter set is used (as is done in this study), in a semi-bounded cascade model the same parameter set could be applied over a range of disaggregation levels as long as a mono-fractal scaling behaviour can be assumed. Based on Veneziano et al. (2006), typical ranges for mono-fractal behaviour are from daily to hourly resolution and from hourly to 5 min resolution.
It should also be noted that the analyses of only the lag-1 autocorrelation is not sufficient, since it provides a limited insight into the process memory. Here, for some stations an overestimation of the lag-1 autocorrelation was identified, but underestimations for lag-6 and lag-36. Hence, a multi-lag analyses is recommended for further studies.
Especially for method C, the general problem of the micro-canonical cascade model of generating time steps with too small rainfall intensities (Molnar and Burlando, 2005; Müller and Haberlandt, 2018) worsened. The MMD approach is introduced to solve this issue. MMD simulates the behaviour of a measurement device (minimum rainfall amount required to cause a registration) after the disaggregation process, eliminating too small rainfall intensities by summing them up to future time steps until the minimum rainfall amount is achieved or exceeded. The MMD approach has a smaller impact on the resulting rainfall characteristics than the choice of methods A, B or C. However, the application of MMD leads to disaggregated time series with a slight better representation of the autocorrelation function. Hence, for the subsequent analyses only the MMD approach is considered. This selection also has the additional advantage that the process of the rainfall measurement itself is simulated.
5.2 Impact of the resampling
To conserve these extreme values a priori without any information about their date of occurrence or their magnitude, a universal definition of extreme rainfall values is introduced. This definition and the connected restrictions for the resampling can be modified in multiple ways to improve the conservation. For example, the applied threshold intensity Itr can be based on a different or an additional (required) return period or duration. Also, a definition of Itr as a quantile of all wet time steps of a disaggregated time series instead of an absolute value would be helpful if there is a high variation of mean rainfall intensities among the investigated stations for an extreme event with a certain duration and return period (which was not the case in this study). However, the extreme values were conserved during the resampling process. The autocorrelation was improved for almost all lags, independent of whether method A, B or C was applied before for the disaggregation. Also, a higher improvement was achieved by the resampling than by the modifications of method B or C.
5.3 Study limitations
This study is focused on the methodological development of the micro-canonical cascade model and on the improvement of the disaggregated time series by a resampling approach as a post-processing strategy. Hence, the study is limited in several aspects.
First of all, the rainfall data set, with 24 rain gauges, is rather small. Although the study area covers different topographical region and climate classes, the resulting time series characteristics are similar and do not cover a wide range. A generalisation of the results has to be proven for regions which are very different from this study area. To draw general conclusions from the point of comparative hydrology future research should include rain gauges from different climate regions and topologies.
Second, based on the similar rainfall characteristics and extreme values, the introduction of the universal extreme value definition was possible and representative for all stations in the study. If stations from different climate regions and topologies are studied as recommended before, it has to be proven (i) if the introduced universal extreme value definition still has the potential to conserve the extreme rainfall values throughout the resampling process and (ii) if Itr has to be redefined (see also the discussion in Sect. 5.2).
Third, as mentioned in Sect. 1, Pearson's autocorrelation is a measure of linear dependency. It only captures the complete dependence structure between random variables if they are jointly Gaussian. An alternative criterion would be Spearman's rank correlation (capturing monotonic but not necessarily linear relationships). In both cases, autocorrelation as a function of lags is only meaningful in the context of second-order stationary stochastic processes (or weakly stationary processes). Rainfall intensities are not normally distributed. Also, rainfall time series present a mixture of processes due to the high intermittency of rainfall amplified by the disaggregation process, changing between the two states of rainfall, occurrence and non-occurrence. Still, every kind of autocorrelation measurement can provide a measure for the similarity of e.g. two time series. Pearson's autocorrelation coefficient is widely used for autocorrelation analyses in hydrology. It is applied in this study to achieve a comparable similarity in the disaggregated time series as is estimated from the observations. Besides the mixture of processes and the limitations of Pearson's autocorrelation as a measure of dependence, the Hurst phenomenon might also offer an additional perspective for the analysis at hand (see Koutsoyiannis, 2009, for an introduction).
Fourth, although method C is based on a finding in Lombardo et al. (2012, 2017), the disaggregation method differs from the additive cascade model in Lombardo et al. (2012, 2017). Hence, the identified problem of non-stationarity of the disaggregation is not solved by the introduced cascade model variants and remains an open challenge for further studies.
Finally, the simulated annealing was implemented in a computationally efficiently way suggested by Bárdossy (1998). After each swap the objective function is not completely newly calculated, but rather updated only for the modified elements of the time series affected by the swap. Nevertheless, the resampling process remains very time-demanding, depending on the chosen parameter setup. More recently published optimisation algorithms are very promising regarding less computational times, e.g. the quantum annealing approach (Heim et al., 2015; Crosson and Harrow, 2016), enabling the optimisation of longer disaggregated rainfall time series or more realisations in the same time.
Three variants of the micro-canonical cascade model (method A, reference from Müller and Haberlandt, 2018, B and C) were assessed regarding their ability to represent the autocorrelation in the disaggregated, 5 min rainfall time series, starting from daily totals. The methods differ regarding the position dependency in the first disaggregation step and the definition of a wet time step during the disaggregation process. The following conclusions are drawn based on the results.
-
The introduction of a position dependency in the first disaggregation step (method B) and especially the introduction of the position dependency (method C) following Lombardo et al. (2012, 2017) lead to an improvement of the autocorrelation.
-
While method A and B lead to quite similar event-based and continuous rainfall characteristics, the results from method C differ significantly.
-
Method C leads to a high fraction of time steps with too small rainfall intensities in the disaggregated time series, which can be corrected using the MMD approach.
For the following investigations, only method combinations with MMD were analysed, since the results indicated a slightly better representation of the autocorrelation function.
After the disaggregation process the simulated annealing resampling algorithm was applied to improve the autocorrelation. The following conclusions are drawn.
- 4.
The resampling leads to an improvement of the autocorrelation, independent of the applied disaggregation method or the investigated lag.
- 5.
The improvement of the autocorrelation by the resampling was higher than by the choice of the cascade model modification.
- 6.
The extreme rainfall values have to be considered during the resampling, otherwise they will be underestimated after the resampling process.
- 7.
With the newly introduced universal definition the extreme rainfall events can be considered without the a priori knowledge of their occurrence and magnitude. Hence, the extreme rainfall values are represented after the resampling process as well as before.
The overall best representation of the autocorrelation was achieved by method C in combination with a resampling approach as post-processing strategy. Urban hydrological simulations would provide additional information about the impact of the different disaggregation methods and the resampling process on simulated hydrographs and flood events, but this is beyond the scope of this study.
The rainfall data are accessible from the Climate Data Center web portal of the German Weather Service (https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/, DWD, 2013). The rainfall disaggregation program as well as the resampling program are both written in Fortran, so only executable files can be shared. However, the author is happy to share them on request.
The supplement related to this article is available online at: https://doi.org/10.5194/hess-24-169-2020-supplement.
The author declares that there is no conflict of interest.
The author thanks Annika Föt and Jonas Legler for their efforts in their student theses related to this paper. The author is also thankful for fruitful discussions with Thomas Müller about the conservation of extreme rainfall values during the resampling and with David Lun about the mathematical background of different aspects. Also, Anne Fangmann and Patrick Hogan are acknowledged for their support with R scripts and useful comments on an early draft of the manuscript, respectively. I am also thankful for the permission to use the data of the German National Weather Service (Deutscher Wetterdienst DWD). Finally, Elena Volpi and two anonymous reviewers as well as Nadav Peleg as associated editor are gratefully acknowledged for their contributions which improved this paper significantly.
This research has been supported by the DFG e.V., Bonn, Germany, as a Research Fellowship (MU 4257/1-1). The author was supported by the TU Wien Library through its Open Access Funding Program.
This paper was edited by Nadav Peleg and reviewed by Elena Volpi and two anonymous referees.
Bardossy, A.: Generating precipitation time series using simulated annealing, Water Resour. Res., 34, 1737–1744, 1998.
Berne, A., Delrieu, G., Creutin, J. D., and Obled, C.: Temporal and spatial resolution of rainfall measurements required for urban hydrology, J. Hydrol., 299, 166–179, 2004.
Blöschl, G. and Sivapalan, M.: Scale issues in hydrological modeling: a review, Hydrol. Process., 9, 251–290, 1995.
Breinl, K. and Di Baldassarre, G.: Space-time disaggregation of precipitation and temperature across different climates and spatial scales, J. Hydrol., Regional studies, 21, 126–146, 2019.
Breinl, K., Strasser, U., Bates, P., and Kienberger, S.: A joint modelling framework for daily extremes of river discharge and precipitation in urban areas, J. Flood Risk Manag., 10, 97–114, 2015.
Burlando, P. and Rosso, R.: Scaling and multiscaling of depth-duration-frequency curves for storm precipitation, J. Hydrol., 187, 45–64, 1996.
Callau Poduje, A. C. and Haberlandt, U.: Short time step continuous rainfall modeling and simulation of extreme events, J. Hydrol., 552, 182–197, 2017.
Carsteanu, A. and Foufoula-Georgiou, E.: Assessing dependence among weights in a multiplicative cascade model of temporal rainfall, J. Geophys. Res., 101, 26363–26370, 1996.
Cristiano, E., ten Veldhuis, M.-C., and van de Giesen, N.: Spatial and temporal variability of rainfall and their effects on hydrological response in urban areas – a review, Hydrol. Earth Syst. Sci., 21, 3859–3878, https://doi.org/10.5194/hess-21-3859-2017, 2017.
Crosson, E. and Harrow, A. W.: Simulated Quantum Annealing Can Be Exponentially Faster Than Classical Simulated Annealing, Proceedings of the 57th Annual Symposium on Foundations of Computer Sciences, New Brunswick, NJ, USA, ISSN 0272-5428, 2016.
Ding, J., Haberlandt, U., and Dietrich, J.: Estimation of instantaneous peak flow from maximum daily flow: a comparison of three methods, Hydrol. Res., 46, 671–688, 2015.
Dunkerley, D. L.: Identifying individual rain events from pluviograph records: a review with analysis of data from an Australian dryland site, Hydrol. Process., 22, 5024–5036, https://doi.org/10.1002/hyp.7122, 2008.
DWA-A 531: Starkregen in Abhängigkeit von Wiederkehrzeit und Dauer, Technical guideline of the DWA, Hennef, 2012.
DWD: Climate Data Center – Climate observations in Germany, available at https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/, 2013.
Föt, A.: Optimization of a resampling-algorithm for the implementation of spatial and temporal consistency in disaggregated time series, Bachelor thesis, Institute of Hydrology and Water Resources Management, Faculty of Civil Engineering and Geodesy, Leibniz Universität Hannover, 2015 (in German).
Güntner, A., Olsson, J., Calver, A., and Gannon, B.: Cascade-based disaggregation of continuous rainfall time series: the influence of climate, Hydrol. Earth Syst. Sci., 5, 145–164, https://doi.org/10.5194/hess-5-145-2001, 2001.
Handwerker, J.: Cell tracking with TRACE3D – a new algorithm, Atmos. Res., 61, 15–34, 2002.
Heim, B., Rønnow, T. F., Isakov, S. V., and Troyer, M.: Quantum versus classical annealing of Ising spin glasses, Science, 348, 215–217, 2015.
Hingray, B. and Ben Haha, M.: Statistical performance of various deterministic and stochastic models for rainfall series disaggregation, Atmos. Res., 77, 152–175, 2005.
Hosking, J. R. M. and Wallis, J. R.: Regional frequency analysis, Cambridge University Press, Cambridge, 1997.
Jarvis, A., Reuter, H. I., Nelson, A., and Guevara, E.: Hole-filled seamless SRTM data V4, International Centre for Tropical Agriculture (CIAT), available at: http://srtm.csi.cgiar.org (last access: 10 August 2009), 2008.
Koutsoyiannis, D.: The Hurst phenomenon and fractional Gaussian noise made easy, Hydrolog. Sci. J., 47, 573–595, 2009.
Koutsoyiannis, D. and Langousis, A.: “Precipitation.” Treatise on water science, edited by: Wilderer, P. and Uhlenbrook, S., Vol. 2, Academic Press, Oxford, 27–78, 2011.
Koutsoyiannis, D. and Onof, C.: Rainfall disaggregation and adjusting procedures on a Poisson cluster model, J. Hydrol., 246, 109–122, https://doi.org/10.1016/S0022-1694(01)00363-8, 2001.
Koutsoyiannis, D., Onof, C., and Wheater, H. S.: Multivariate rainfall disaggregation at a fine time scale, Water Resour. Res., 39, 1173, https://doi.org/10.1029/2002WR001600, 2003.
Kumar, P., Guttarp, P., and Foufoula-Georgiou, E.: A probability-weighted moment test to assess simple scaling, Stoch. Hydrol. Hydraul., 8, 173–183, 1994.
Legler, J.: Optimization of autocorrelation in disaggregated time series and validation with an urban hydrological model, Master thesis, Institute of Hydrology and Water Resources Management, Faculty of Civil Engineering and Geodesy, Leibniz Universität Hannover, 2017 (in German).
Licznar, P., Schmitt, T. G., and Rupp, D. E.: Distributions of Microcanonical Cascade Weights of Rainfall at Small Timescales, Acta Geophys., 59, 1013–1043, 2011.
Licznar, P., De Michele, C., and Adamowski, W.: Precipitation variability within an urban monitoring network via microcanonical cascade generators, Hydrol. Earth Syst. Sci., 19, 485–506, https://doi.org/10.5194/hess-19-485-2015, 2015.
Lisniak, D., Franke, J., and Bernhofer, C.: Circulation pattern based parameterization of a multiplicative random cascade for disaggregation of observed and projected daily rainfall time series, Hydrol. Earth Syst. Sci., 17, 2487–2500, https://doi.org/10.5194/hess-17-2487-2013, 2013.
Lombardo, F., Volpi, E., and Koutsoyiannis, D.: Rainfall downscaling in time: theoretical and empirical comparison between multifractal and Hurst-Kolmogorv discrete random cascades, Hydrolog. Sci. J., 57, 1052–1066, 2012.
Lombardo, F., Volpi, E., Koutsoyiannis, D., and Papalexiou, S. M.: Just two moments! A cautionary note against use of high-order moments in multifractal models in hydrology, Hydrol. Earth Syst. Sci., 18, 243–255, https://doi.org/10.5194/hess-18-243-2014, 2014.
Lombardo, F., Volpi, E., Koutsoyiannis, D., and Serinaldi, F.: A theoretical consistent stochastic cascade for temporal disaggregation of intermittent rainfall, Water Resour. Res., 53, 4586–4605, 2017.
Mandelbrot, B.: Intermittent turbulence in self-similar cascades – divergence of high moments and dimension of carrier, J. Fluid Mech., 62 331–358, 1974.
Marshak, A., Davis, A., Cahalan, R., and Wiscombe, W.: Bounded cascade models as nonstationary multifractals, Phys. Rev. E, 49, 55–69, 1994.
Menabde, M. and Sivapalan, M.: Modeling of rainfall time series and extremes using bounded random cascades and levy-stable distributions, Water Resour. Res., 36, 3293–3300, https://doi.org/10.1029/2000WR900197, 2000.
Menabde, M., Harris, D., Seed, A., Austin, G., and Stow, D.: Multiscaling properties of rainfall and bounded random cascades, Water Resour. Res., 33, 2823–2830, 1997.
Molnar, P. and Burlando, P.: Preservation of rainfall properties in stochastic disaggregation by a simple random cascade model, Atmos. Res., 77, 137–151, 2005.
Müller, H. and Haberlandt, U.: Temporal rainfall disaggregation with a cascade model: from single-station disaggregation to spatial rainfall, J. Hydrol. Eng., 20, 04015026, https://doi.org/10.1061/(ASCE)HE.1943-5584.0001195, 2015.
Müller, H. and Haberlandt, U.: Temporal rainfall disaggregation using a multiplicative cascade model for spatial application in urban hydrology, J. Hydrol., 556, 847–864, 2018.
Müller-Thomy, H. and Sikorska-Senoner, A.: Does the complexity in temporal precipitation disaggregation matter for a lumped hydrological model?, Hydrolog. Sci. J., 64, 1453–1471, 2019.
Müller-Thomy, H., Wallner, M., and Förster, K.: Rainfall disaggregation for hydrological modeling: is there a need for spatial consistence?, Hydrol. Earth Syst. Sci., 22, 5259–5280, https://doi.org/10.5194/hess-22-5259-2018, 2018.
Ochoa-Rodriguez, S., Wang, L.-P., Gires, A., Pina, R. D., Reinoso-Rondinel, R., Bruni, G., Ichiba, A., Gaitan, S., Cristiano, E., Assel, J. v., Kroll, S., Murlà-Tuyls, D., Tisserand, B., Schertzer, D., Tchiguirinskaia, I., Onof, C., Willems, P., and ten Veldhuis, M.-C.: Impact of Spatial and Temporal Resolution of Rainfall Inputs on Urban Hydrodynamic Modelling Outputs: A Multi-Catchment Investigation, J. Hydrol., 531, 389–407, 2015.
Olsson, J.: Evaluation of a scaling cascade model for temporal rain- fall disaggregation, Hydrol. Earth Syst. Sci., 2, 19–30, https://doi.org/10.5194/hess-2-19-1998, 1998.
Over, T. M. and Gupta, V. K.: Statistical Analysis of mesoscale rainfall: dependence of a random cascade generator on large-scale forcing, J. Appl. Meteorol., 33, 1526–1542, 1994.
Paschalis, A., Molnar, P., and Burlando, P.: Temporal dependence structure in weights in a multiplicative cascade model for precipitation, Water Resour. Res., 48, W01501, https://doi.org/10.1029/2011WR010679, 2012.
Paschalis, A., Molnar, P., Fatichi, S., and Burlando, P.: On temporal stochastic modeling of precipitation, nesting models across scales, Adv. Water Resour., 63, 152–166, 2014.
Peel, M. C., Finlayson, B. L., and McMahon, T. A.: Updated world map of the Köppen-Geiger climate classification, Hydrol. Earth Syst. Sci., 11, 1633–1644, https://doi.org/10.5194/hess-11-1633-2007, 2007.
Pohle, I., Niebisch, M., Müller, H., Schümberg, S., Zha, T., Maurer, T., and Hinz, C.: Coupling Poisson rectangular pulse and multiplicative micro-canonical random cascade models to generate sub-daily precipitation time series, J. Hydrol., 562, 50–70, 2018.
Rupp, D. E., Keim, R. F., Ossiander, M., Brugnach, M., and Selker, J.: Time scale and intensity dependency in multiplicative cascades for temporal rainfall disaggregation, Water Resour. Res., 45, W07409, https://doi.org/10.1029/2008WR007321, 2009.
Schilling, W.: Univariate versus Multivariate Rainfall Statistics – Problems and Potentials (A Discussion), Water Sci. Technol., 16, Copenhagen, Denmark, 139–146, 1984.
Schilling, W.: Rainfall data for urban hydrology: what do we need?, Atmos. Res., 27, 5–21, 1991.
Veneziano, D., Langousis, A., and Furcolo, P.: Multifractality and rainfall extremes: A review, Water Resour. Res., 42, W06D15, https://doi.org/10.1029/2005WR004716, 2006.
Serinaldi, F.: Multifractality, imperfect scaling and hydrological properties of rainfall time series simulated by continuous universal multifractal and discrete random cascade models, Nonlin. Processes Geophys., 17, 697–714, https://doi.org/10.5194/npg-17-697-2010, 2010.
Storm, R.: Wahrscheinlichkeitsrechnung, mathematische Statistik und statistische Qualitätskontrolle, VEB Fachbuchverlag, Leipzig, 9th edition, 360 pp., 1988.
Svensson, C., Olsson, J., and Berndtsson, R.: Multifractal properties of daily rainfall in two different climates, Water Resour. Res., 32, 2463–2472, 1996.
Westra, S., Mehrotra, R., Sharma, A., and Srikanthan, R.: Continious rainfall simulation: 1. A regionalized subdaily disaggregation approach, Water Resour. Res., 48, W01535, https://doi.org/10.1029/2011WR010489, 2012.
Wójcik, R. and Buishand, T. A.: Simulation of 6-hourly rainfall and temperature by two resampling schemes, J. Hydrol., 273, 69–80, 2003.
Yu, P.-S., Yang, T.-C., and Lin, C.-S.: Regional rainfall intensity formulas based on scaling property of rainfall, J. Hydrol., 295, 108–123, 2014.