the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 29 May 2020
| 29 May 2020
Modelling rainfall with a Bartlett–Lewis process: new developments
Li-Pen Wang
The use of Poisson cluster processes to model rainfall time series at a range of scales now has a history of more than 30 years. Among them, the randomised (also called modified) Bartlett–Lewis model (RBL1) is particularly popular, while a refinement of this model was proposed recently (RBL2; Kaczmarska et al., 2014). Fitting such models essentially relies upon minimising the difference between theoretical statistics of the rainfall signal and their observed estimates. The first statistics are obtained using closed form analytical expressions for statistics of the orders 1 to 3 of the rainfall depths, as well as useful approximations of the wet–dry structure properties. The second are standard estimates of these statistics for each month of the data. This paper discusses two issues that are important for the optimal model fitting of RBL1 and RBL2. The first issue is that, when revisiting the derivation of the analytical expressions for the rainfall depth moments, it appears that the space of possible parameters is wider than has been assumed in past papers. The second issue is that care must be exerted in the way monthly statistics are estimated from the data. The impact of these two issues upon both models, in particular upon the estimation of extreme rainfall depths at hourly and sub-hourly timescales, is examined using 69 years of 5 min and 105 years of 10 min rainfall data from Bochum (Germany) and Uccle (Belgium), respectively.
Please read the corrigendum first before continuing.
-
Notice on corrigendum
The requested paper has a corresponding corrigendum published. Please read the corrigendum first before downloading the article.
-
Article
(5505 KB)
- Corrigendum
-
Supplement
(1904 KB)
-
The requested paper has a corresponding corrigendum published. Please read the corrigendum first before downloading the article.
- Article
(5505 KB) - Corrigendum
-
Supplement
(1904 KB) - BibTeX
- EndNote





Rainfall is the main input to a range of models in geophysics such as hydrological catchment models, sewerage discharge models and erosion models. Therefore, to understand the behaviour of catchment runoff, sewer flows or soil erosion, it is necessary to have access to precipitation data sets at the characteristic response scales of these variables. There are also other non-geophysical applications which require such data sets, for instance the investigation of the frequency of outages in telecommunications data. For all such applications, hourly and sub-hourly rainfall data are required. The availability of data sets that are long enough to represent the range of variability of precipitation at such scales is however limited, even in developed countries. This is why the availability of a stochastic model able to generate realistic time series of rainfall depths at a range of scales is very useful. There is already a considerable amount of literature in this area (Connolly et al., 1998; Arnbjerg-Nielsen, 2012; Arnbjerg-Nielsen et al., 2013; Onof and Arnbjerg-Nielsen, 2009; Wang et al., 2010): the present paper is a contribution to the improvement of the performance of a particular type of stochastic rainfall models.
Depending upon the application, “realistic” will mean different things. For applications that are related to design, realistic will involve the reproduction of the observed extreme behaviour of the precipitation process at a range of timescales. Onof and Arnbjerg-Nielsen (2009) and Arnbjerg-Nielsen (2012), for example, integrated two stochastic models to eventually generate 5 min point rainfall time series from 1 h 10 km RCM (regional climate model) output. This method enables the consideration of the impact of climate change in urban sewer system design.
In this paper, we focus upon one approach to rainfall modelling, that which is based upon the use of point processes as defining the times at which the building blocks of the model, i.e. rainfall cells, arrive. These cells are conceptual ones, although their typical characteristics are those of small mesoscale areas (SMSAs) which are embedded in large mesoscale areas (Burlando and Rosso, 1993). The presence of clustering means that a homogeneous Poisson point process is not an appropriate choice for the underlying process of cell arrivals. Two options are available. The first introduces randomness by having the Poisson rates behave as a continuous-time Markov chain: this defines a Cox (doubly stochastic) process (see Ramesh, 1995; Ramesh et al., 2018).
The second explicitly models the clustering process. This can be by defining the number cells in a storm as a random variable, with another random variable modelling the delays from the storm to the cell arrival time. This defines a Neyman–Scott process (see Cowpertwait, 1998; Evin and Favre, 2008; Paschalis et al., 2014). Alternatively, a second homogeneous Poisson process defines the cell arrival times over a duration of storm activity that defines a random variable (see Onof and Wheater, 1993; Khaliq and Cunnane, 1996; Verhoest et al., 1997; Kossieris et al., 2018). For both Poisson cluster processes, the SMSAs are then represented by rectangular pulses corresponding to a random constant rainfall intensity over a random duration. In this paper, the Bartlett–Lewis process is the chosen point process model.
Two issues have been flagged in the literature which limit the applicability of a number of variants of the basic model type published in 1987 (Rodriguez-Iturbe et al., 1987). The first one is well-known (e.g. Verhoest et al., 2010). Many studies have shown that rectangular pulse models underestimate hourly extremes (Verhoest et al., 2010, and references therein). This is often accompanied by an overestimation of daily extremes. The other, less well known problem was identified by Marani (2003). While one of the strengths of models based upon Poisson cluster processes is their ability to capture rainfall variability over a range of scales (hence its use in disaggregation; see Koutsoyiannis and Mamassis, 2001), they underestimate this variability for scales equal to or larger than a few days.
Both issues are closely connected to fundamental features of these models and of the way they are fitted. The first arises partly due to the fact that the model is calibrated in such a way as to reproduce the mean behaviour of the precipitation process. That is, statistics like the mean, variance and autocovariance of rainfall totals at timescales varying from 1 to 24 h are used to fit the models. As far as the cell intensity parameters are concerned, these statistics are functions of their first- and second-order moments only. The rest of this distribution is not thereby determined, although the choice of distribution has a clear impact upon the extremes (Onof and Wheater, 1994). This situation can be partially addressed by including the coefficients of skewness (hereafter, “skewness”) of the rainfall depths at relevant timescales as additional statistics in the calibration of the model (Cowpertwait, 1998). Kaczmarska et al. (2014) similarly find that the inclusion of the skewness yields reasonable performance and extend the range of timescales to include sub-hourly scales which are of key importance in urban hydrology, erosion studies and telecommunications applications. There remains however the option of using a fat-tailed distribution for the cell intensity to achieve further improvement. To see whether this is advisable or useful, we need to get a better picture of what produces the extremes at different timescales. Is it predominantly the superposition of several cells, or is it mostly the rainfall produced by a single cell? In the latter case, the choice of a different distribution of rainfall intensities is a key decision.
The other issue, namely that of the reproduction of the variability of rainfall depths across scales, had not so far received much attention, although it is in fact of clear practical importance. If we want the model to be able to capture longer-term variability (as would certainly be required to reproduce climate variability for instance), then this issue must be addressed. The most promising ways forward in this respect come from combining the Poisson cluster model with a coarse-scale model that captures much of the longer-term variability (Park et al., 2019) or from letting climatological information guide the weighting to be assigned to different months in the data in calibrating the model (Kaczmarska et al., 2015; Cross et al., 2020). Both approaches represent important developments. The first approach involving the combination of two models has the advantage of enabling a much improved reproduction of extreme rainfall depths. The second approach, which incorporates climatological information, enables this model to be used as a weather generator in climate impact studies.
While the use of extraneous (e.g. climatological) information and the combination with another (e.g. coarse-scale) model are the most promising ways in which this area of stochastic rainfall modelling is developing, the issue of how the Poisson cluster model is fitted to rainfall statistics needs to be revisited. In this paper, we address two hitherto unnoticed issues with random-parameter Bartlett–Lewis rainfall models. First, we draw attention to a claim made in the original publication of the randomised Bartlett–Lewis model (Rodriguez-Iturbe et al., 1988) which involves an erroneous assessment of the mathematically feasible limits of a key model parameter. Correcting this misspecification of the constraints on this parameter allows us to consider a broader parameter space, thereby potentially including parameter values that will improve model performance. Second, we show the importance of the choice of estimators for the statistics used in model fits to individual months. We shall show that, by taking both issues into account, it is possible to improve the reproduction of extreme rainfall depths over a range of scales. A detailed examination of the impact upon the variance function will be carried out in another paper.
This paper starts with a presentation of the data and a reminder of the structure of three versions of the Bartlett–Lewis Rectangular Pulse model, as well as of how these models are fitted. The revised equations for the statistics of the orders 1 to 3 of the rainfall depths at aggregation scale h h are then presented. In the following section, we discuss the estimation of standard monthly statistics and show the bias that can be introduced through the use of a commonly used type of estimator. In the final section, we consider the impact of the new equations and unbiased estimation method upon the reproduction of standard statistics and extremes of rainfall depths.
Rain gauge rainfall data of 5 min from a rain gauge in Germany (North Rhine-Westphalia) and one in Belgium (Flanders, Brussels region) are used to demonstrate the new developments in model (population) and data (sample) statistics for model fitting described in this paper. These are:
-
Bochum for 69 years of 5 min data from January 1981 to December 1999
-
Uccle for 105 years of 10 min data from January 1898 to December 2002.
Because of constraints on the length of the paper, the results for Uccle are shown only in the Supplement of this paper.
Additionally, for the purpose of the numerical investigation of estimators, Greenwich (14.5 years of 5 min data from February 1987 to July 2001) data are used.
In the original Bartlett–Lewis Rectangular Pulse (OBL) model (as illustrated in Fig. 1), storms arrive according to a Poisson process at rate λ. Another process generates cells associated with each storm: this is also a Poisson process, triggered by the storm arrival (rate β) and active over a duration that is exponentially distributed with parameter γ. These cells have an exponential duration (parameter η) and a random depth (described by its first three – non-centred – moments: μx, μx2 and μx3).
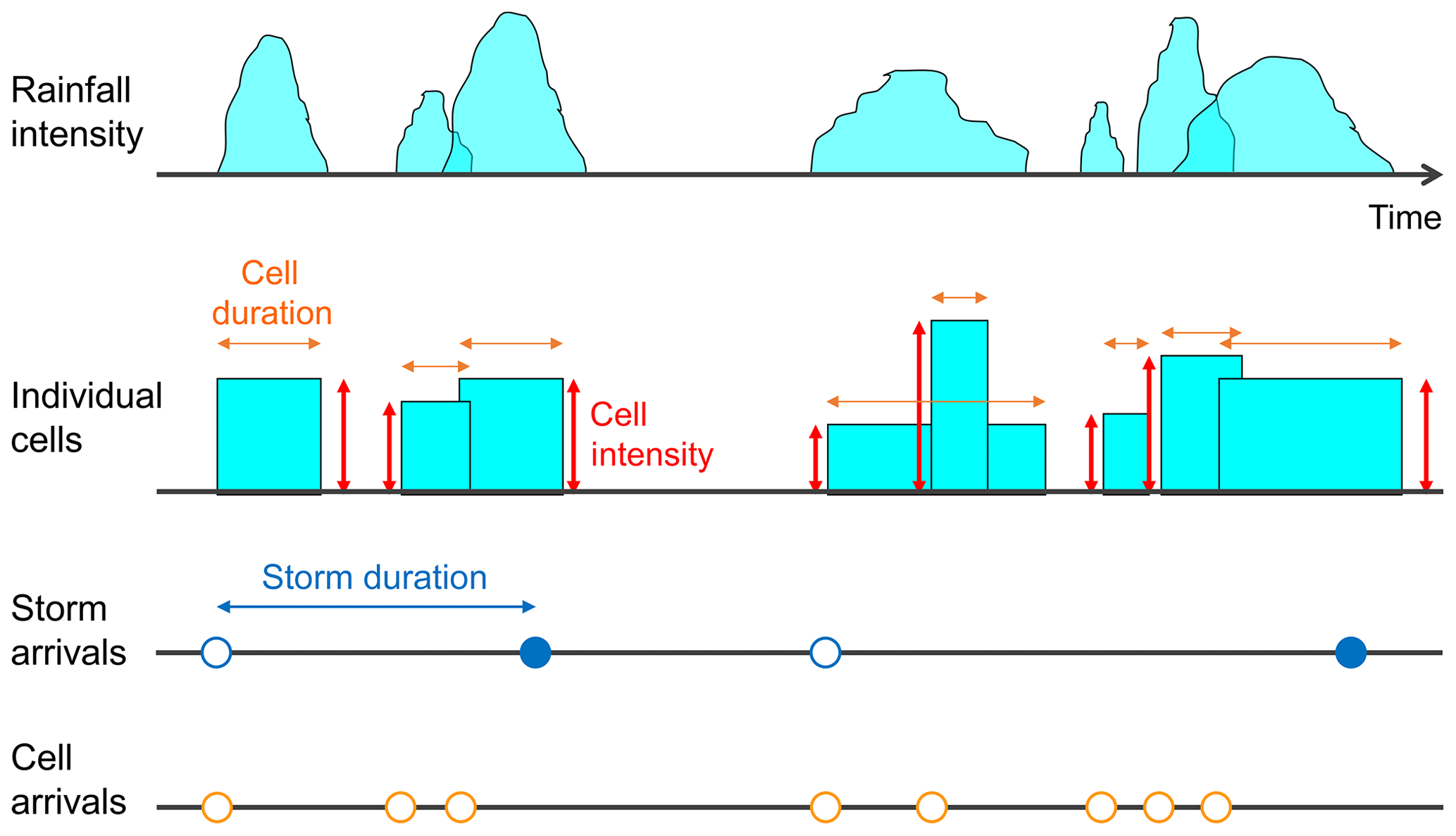
Figure 1Illustration of the conceptualisation of the Bartlett–Lewis Rectangular Pulse model.
Further development of the original model proposed by Rodriguez-Iturbe et al. (1987) involved has in particular focused upon the randomisation of the temporal structure of storms for the Bartlett–Lewis process (Rodriguez-Iturbe et al., 1988; Onof and Wheater, 1993). The temporal structure of precipitation is allowed to vary from storm to storm by randomising parameter η. This can be chosen as a gamma-distributed Gamma() random variable that varies between storms. The cell arrival rate and storm duration parameter are scaled accordingly: β=κη and γ=ϕη. This will be referred to as the randomised Bartlett–Lewis model version 1 (RBL1).
Recently, this randomisation strategy was extended to include all the parameters describing the internal structure of the storm, i.e. to include parameter μx (Kaczmarska et al., 2014). μx is now a random variable that takes on different values for different storms, proportionally to η: μx=ιη. This is the randomised Bartlett–Lewis model version 2 (RBL2). This model was shown to outperform OBL and RBL1 by Kaczmarska et al. (2014), but
-
only one data set was examined in that study, so this conclusion cannot be generalised;
-
RBL1 was excluded from the comparison because the authors “concluded that the improvement in the fit to proportion dry that had previously been found by randomising η was at the expense of a deterioration in the fit to the skewness” (Kaczmarska et al., 2014); but given the popularity and successful application of this model to a range of types of rainfall (e.g. see Onof et al., 2000), we decided to include it here for further analysis.
4.1 Calibration
The OBL, RBL1 and RBL2 models generate rainfall as a continuous-time process, {Y(t)}t∈ℝ, where Y(t) is the continuous-time rainfall intensity at time t resulting from the superposition of the intensities of all the cells active at time t. Rainfall records are, however, available in aggregated form for discrete timescales. The rainfall depth for a level of aggregation h h is given by
Analytical expressions of the moments of the aggregated process have been derived as functions of the model parameters. Expressions for other statistical descriptors, such as the proportion of dry periods at timescale h, have also been derived (see Onof et al., 2000). In Sect. S3 in the Supplement to this paper, we provide more efficient approximations of the proportion dry than in earlier papers (see Wheater et al., 2006).
The models are generally calibrated using a generalised method of moments. That is, the model parameters are chosen so that the model values calculated with the available analytical expressions are as close as possible to the empirical values of these statistics obtained from observed data. This is achieved by minimising an objective function:
where Ω is a set of statistical descriptors, ω(ℳ) is a weight assigned to that property in the objective function and is the estimate of that property from the sample of available data. For details about the optimal choices of the weights, see Kaczmarska et al. (2014).
In this paper, following the best practise suggested in Kaczmarska et al. (2014), we choose mean 1 h rainfall depth and coefficient of variation, lag-1 autocorrelation and the coefficient of skewness at 5 or 10 min (5 min for Bochum; 10 min for Uccle), 1, 6 and 24 h timescales as statistical descriptors for the model calibration. In addition, inspired by the optimisation method proposed in Efstratiadis et al. (2002), we used the simulated annealing algorithm to search a promising region and then the downhill simplex Nelder–Mead algorithm to identify the optimum to minimise Eq. (2). The minimum objective function values for all RBL models under consideration in this paper using Bochum data are summarised in Table 5. It is worth noting that the minimum objective function values of RBL2-bM (block) model are comparable with those of the BLRPRx (random-parameter Bartlett–Lewis Rectangular Pulse Model with dependent intensity duration) model given in Table 2 in Kaczmarska et al. (2014), which indicates that there is consistency between the calibration procedures in these two papers.
Below, we present the methodology used to derive the new equations for the two randomised versions of the Bartlett–Lewis model.
4.2 Derivation of the new equations
As explained in Rodriguez-Iturbe et al. (1988), the mean and variance of RBL1 – and this also applies to RBL2 – are obtained by taking means over η of these moments for OBL. This is the case because the expressions of these moments only contain terms corresponding to contributions from single storms, i.e. λqηp terms with q=1 only, as can be seen from the equations obtained by Rodriguez-Iturbe et al. (1987). The same goes for the derivation of the third-order centred moment.
In this section, we focus upon the derivation of the variance of RBL1. The complete sets of new equations for RBL1 and RBL2 are presented in Appendix A.
The starting point for the derivation is the equation for the variance of the OBL model. Here, rather than use the original OBL model parameters (Rodriguez-Iturbe et al., 1987), i.e.
we replace the second and third parameters by dimensionless parameters ϕ and κ that are also used in RBL1 and RBL2 so that the parameterisation of OBL is now in terms of
where γ=ϕη and β=κη.
In the analytical expression for the OBL variance, we make the dependence upon parameter η explicit by referring to it as V(h,η), This distinguishes it from the corresponding variances for RBL models denoted V(h). The OBL variance is
where and . For more on the choice of these parameters, see Sect. S1 in the Supplement.
When deriving the expression for a moment ℳ in the RBL models, we multiply the corresponding moment ℳ(η) for the OBL model by the density function f of the gamma distribution Gamma() of η and integrate over all possible values of η:
where the density function of the gamma distribution is given by
The issue of the convergence of these integrals has, however, not been addressed explicitly in the literature (aside from a mention in Kaczmarska et al., 2014). The integration involves integrals of the following general type evaluated at l=0:
where Γ(s) is the (complete) gamma function and Γ(s,x) is the incomplete gamma function, defined as
When l=0, the integration in Eq. (5) is possible (i.e. the integral is finite) if and only if the integrand is integrable in the neighbourhood of 0, since there are no problems of convergence at ∞. And if the integration is possible for l=0, the expression in Eq. (5) can be simplified using the properties of the gamma function. This will however not be of use here, since we are not considering such integrals separately, as we shall see below.
If we look at the terms the integrand comprises for the statistics that are used to fit the model, we find that they behave in the neighbourhood of 0 as ηα−n with n=2 for the mean rainfall intensity, n≤4 for its variance and covariance and n≤5 for its third-order central moment. The integrals of such terms converge as long as , i.e. .
It therefore seems that, for RBL1, V(h) is finite as long as α>3. Similarly, as the expressions in Appendix A2 show, the mean M(h) is finite as long as α>1, the lag-k covariance C(k,h) is finite when α>3 and the third-order centred moment S(h) is finite when α>4.
This conclusion is however too hasty. Indeed, it involves considering separately the integration of each additive term in Eq. (3). It is with such separate integration that the expressions for the variance and covariance used in Rodriguez-Iturbe et al. (1988) are obtained, and these expressions were used in subsequent research.
Insofar as only moments of orders less than 3 were used in past studies (the third-order moment for RBL1 was only published in a report by Onof et al., 2013, and therefore not used in most of the literature), the constraint α>3 applied to the fits found in these past papers (e.g. Rodriguez-Iturbe et al., 1988; Khaliq and Cunnane, 1996; Verhoest et al., 1997, 2010; Onof et al., 2000; Kim et al., 2017). However, since the issue of the convergence of these integrals was not examined, it is not surprising to find, in most of these studies, that values of α below 3, i.e. outside the domain of feasibility of the optimisation, are obtained for some months. The parameter sets for these months are thus not feasible and a fortiori not optimal. Note that this issue would not easily have been picked up during model calibration because it would not typically have led to unrealistic values of these statistics. In particular, we found that, as long as we keep α<2 (as is the case in the literature), the variance remains positive for typical values of the other parameters.
But aside from this consequence, we now need to check whether, when proceeding without separating the integration into the sum of integrals of the additive terms in the integrand, the domain of convergence of the integral is still defined by for the variance (and for the covariance and for the third-order moment). That is, are any values of α for which the individuals integrals diverge but the integral of the whole integrand does not? That would be the case for instance if, in the neighbourhood of 0, the terms leading to a divergence for certain values of α were to cancel out (for a simple example of individual integrals diverging while, when summed, the total integral does not diverge, see Sect. S2 in the Supplement). Insofar as this is the case, as we shall see below, this will lead to a broadening of the space of feasible parameters as compared with what has been assumed in many studies, with new equations for the extended part of the parameter space. The consequence is that we cannot be certain that the parameters found in these previous studies are optimal.
In line with Eq. (4), the variance V(h) of the RBL1 model is obtained as
and if we choose a small value η0 of η, this integral is the sum
whereby only the first integral has a limited domain of convergence. Let us call this first term V1(h).
From Eq. (3), we have
By doing first- and second-order expansions of the exponential terms, we find that the ηα−4 and ηα−3 terms cancel so that after some algebra, we get
which yields
as long as , i.e. α>1. Otherwise, V1(h) is infinite.
This second term V2(h) is thus calculated as
so that the total variance is
In practice, η0 should be chosen as small as is computationally possible, since it is the term V1(h) that involves the approximation. Figure 2 shows, for some typical parameter values, how sensitive the expressions of V(h) (blue line), as well as C(1,h) and S(h) (grey and orange lines; see derivations below), are to the choice of η0. As can be seen, values start to be much less insensitive to the change of η0 as η0<0.01. In this paper, η0=0.001 is chosen.
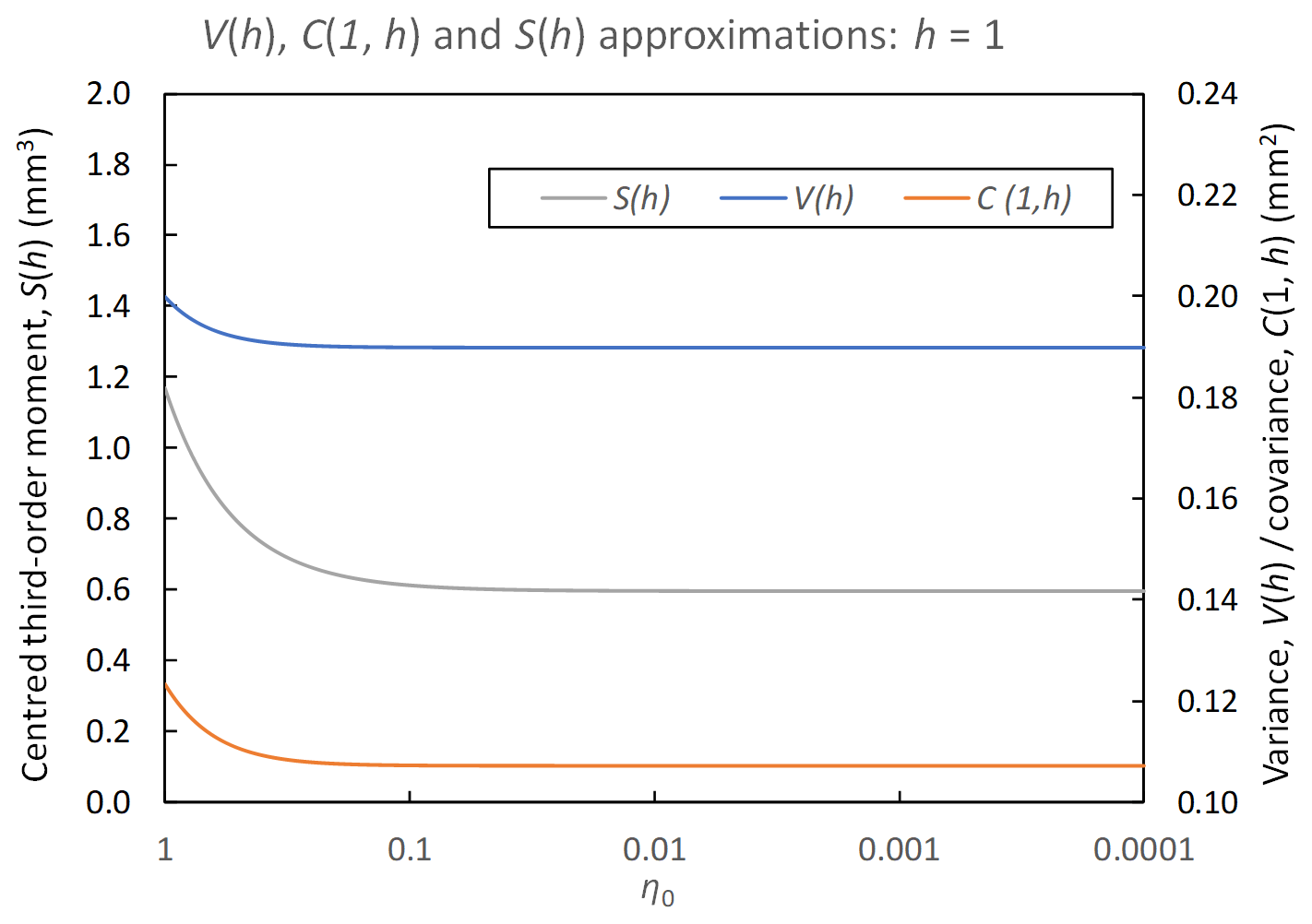
Figure 2Changes of variance (V(h)), lag-1 autocovariance (C(1,h)) and the third-order centred-moment (S(h)) approximations at a 1 h timescale (h=1) for . Parameters used are λ=0.025, μx=1.3, α=2.5, ν=0.28, κ=0.65 and ϕ=0.04.
As indicated, similar derivations yield the expressions for the lag-k covariance C(k,h) and the centred third-order moment S(h) of RBL1.
For RBL2, μx is now random and chosen to be proportional to η as μx=ιη so that shorter cells will tend to have greater intensity. The model equations for RBL2 are therefore obtained from those of OBL by, first, substituting ιη for μx in the expressions for the OBL model moments and then proceeding as for RBL1, i.e. integrating these moments multiplied by the density function of the gamma distribution of η. For this model, the constraint upon α obtained when carrying out separate integrations of the additive terms for the moments of the rainfall depth is less stringent than for RBL1. If we look at terms the integrands comprise, we find that, for RBL2, they behave in the neighbourhood of 0 as ηα−n with n=1 for the mean and n≤2 for the variance, covariance and the third-order moment. The integrals of such terms converge as long as , i.e. .
Analogously to RBL1, it therefore seems that M(h) is finite as long as α>0 and V(h), C(k,h) and S(k,h) are finite as long as α>1. But this conclusion is only warranted for the mean. For the other statistics, Taylor expansions of the exponential terms in the neighbourhood of 0 yield approximations for which the integrals are finite for certain values of α for which the individual additive terms are not integrable. The results are shown in Appendix A3.
5.1 Standard or block estimation?
In fitting Poisson cluster models, it is standard to consider parts of the year separately, e.g. seasons or generally months, and to estimate parameter sets for each of these parts. These parts define blocks of data in the full time series of observed rainfall. The question then arises as to how to deal with data presenting this block structure. The approach used in many papers and certainly that which was implemented in the early papers that used data from the whole year (e.g. Onof and Wheater, 1993) consisted in treating the data between the blocks of interest (e.g. those corresponding to a given calendar month) as missing data. The standard estimators were then used for the moments of the orders 1 to 3 and the proportions of wet periods at the timescales of interest.
Work on the representation of the uncertainty in the model parameters (Wheater et al., 2006) and on the optimal weights to be used in the generalised method of moments implemented in the fitting (Jesus and Chandler, 2011) involved calculating statistics for each block of data of interest (e.g. each month of a given calendar month). This led to the use of other estimators, which we refer to as block estimators of the rainfall statistics. These are obtained by calculating the standard statistic of interest for each block and averaging over the blocks (e.g. each month of a given calendar month). The purpose of this section is to investigate the impact this might have upon the type of statistics used in Poisson cluster rectangular pulse model calibration and not to make any more general points about these two approaches to estimating statistics.
Note that, in the analytical developments below, we used biased but asymptotically unbiased estimates of the variance (i.e. the sum of squares is divided by the sample size without subtracting 1), which considerably simplifies the algebra in comparing the standard and block estimators. Because of the large sample sizes, the bias introduced is negligible, in particular in comparison with the difference we identify between standard and block estimators. To confirm this, the numerical results we provide use the unbiased estimators.
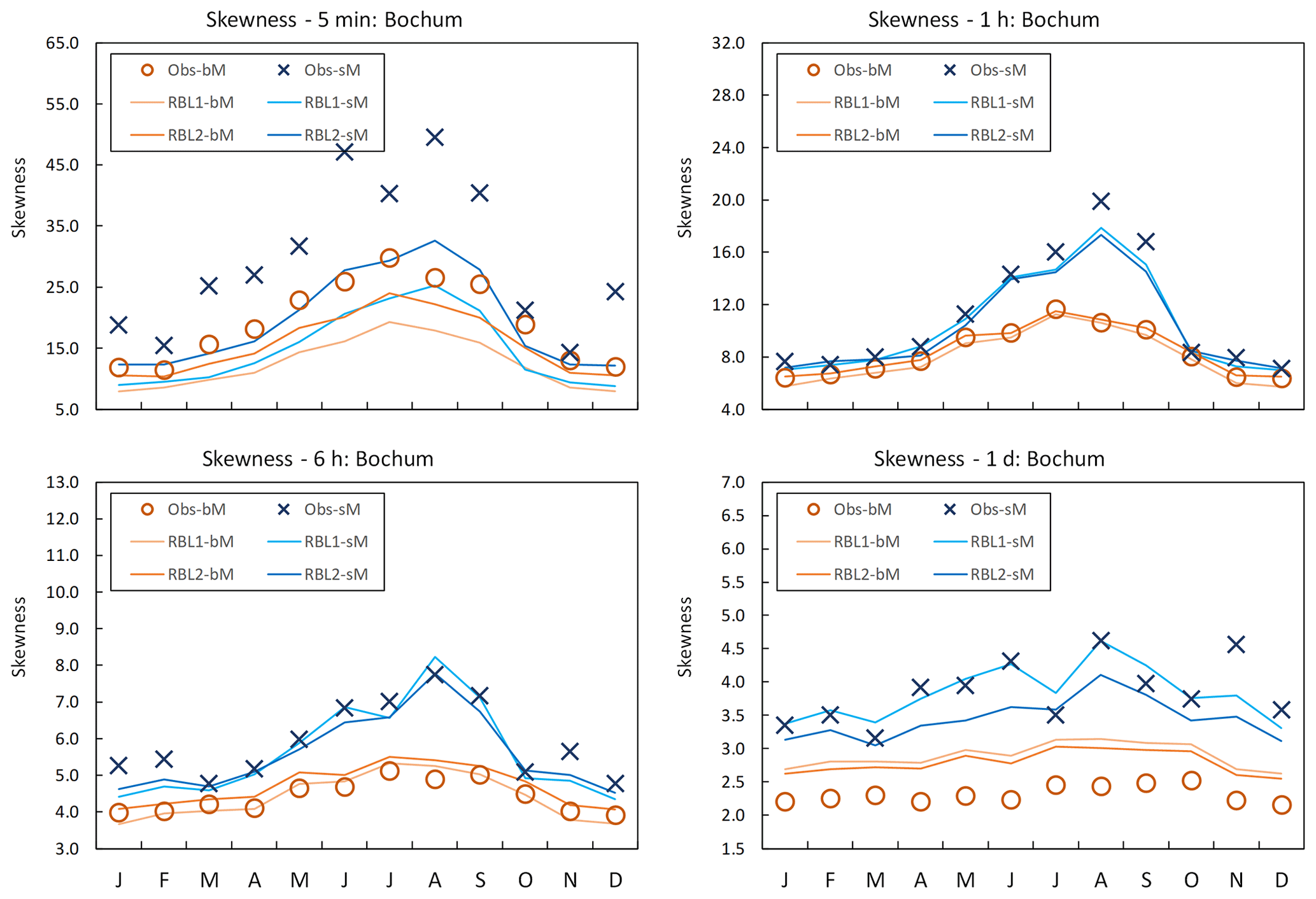
Figure 3Coefficient of skewness by month at Bochum: the observed coefficient of skewness calculated with block (Obs-bM, orange circle markers) vs. standard (Obs-sM, blue cross markers) methods, the same with the RBL1 (RBL1-bM, light orange line; RBL1-sM, light blue line) models and the same with RBL2 (RBL2-bM, orange lines; RBL2-sM, blue lines) models.
There is no difference between the two methods as far as the estimate of the mean rainfall intensity for calendar month m and timescale h is concerned:
where Ny is the number of years; Nm,h is the number of timesteps at scale h in a month of calendar month m (for all months except February for which leap years would lead to a more complicated formula); and extends the notation introduced at the start of the paper: it is the rainfall depth in the ith interval of the jth month of calendar month m.
This is however no longer the case with the variance Vm,h of the rainfall intensity for calendar month m and timescale h for which the standard and block (biased) estimates are respectively
where for are the (sample) mean depths at timescale h of the jth month of calendar month m.
A little algebra shows a result that is also familiar from an ANalysis Of VAriance (ANOVA), i.e. that the two estimators are related by
where the added term is the (biased) sample variance of the above averages.
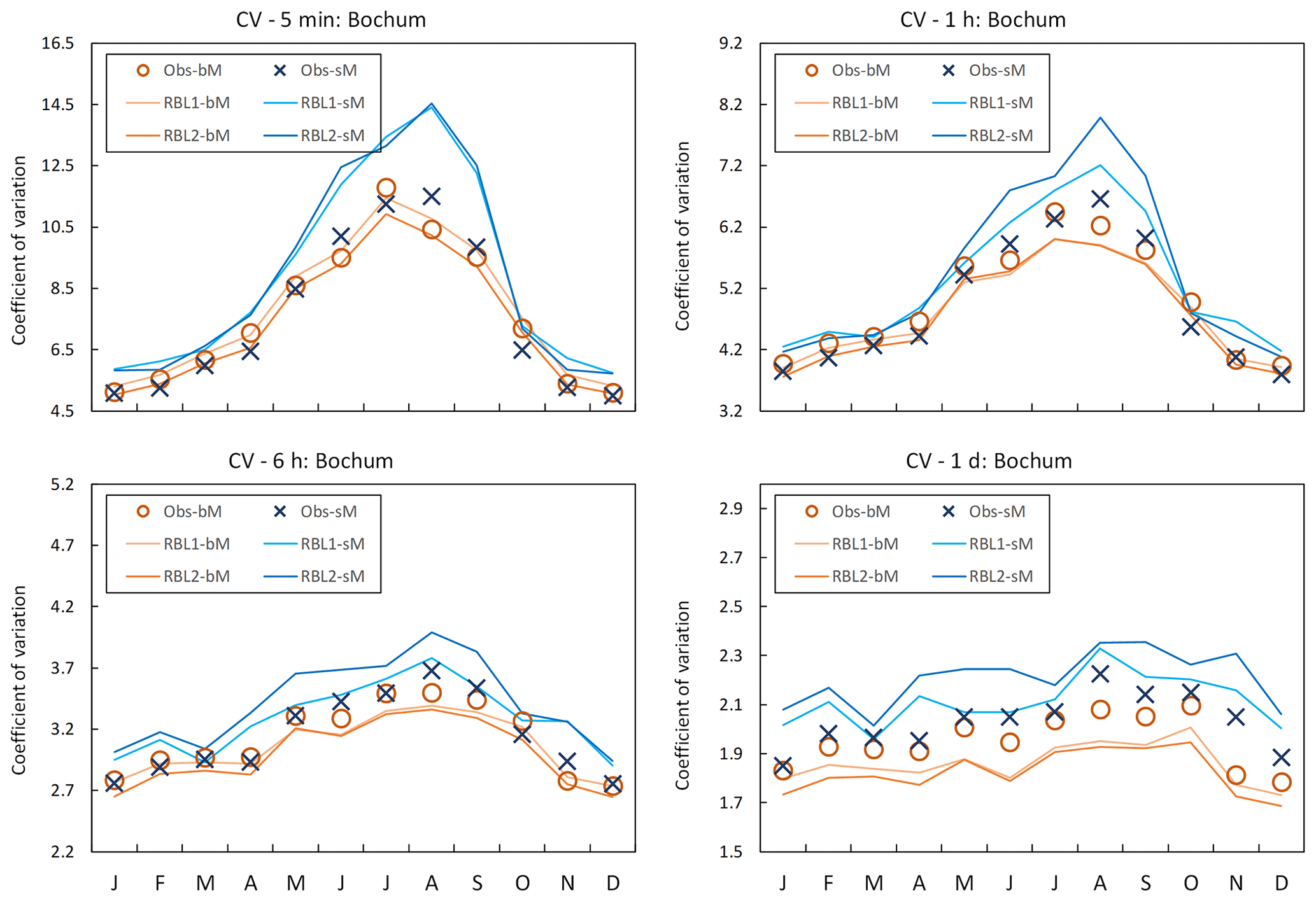
Figure 4Coefficient of variation (CV) by month at Bochum: the observed calculated CV with block (Obs-bM, orange circle markers) vs. standard (Obs-sM, blue cross markers) methods, CV fitted with the RBL1 (RBL1-bM, light orange line; RBL1-sM, light blue line) models, and CV fitted with the RBL2 (RBL2-bM, orange lines; RBL2-sM, blue lines) models.
With the third-order centred moments, we also have two distinct expressions for their estimators
which are related by the following equation
where is the third-order centred moment.
5.2 A brief analytical and numerical investigation: are the estimators significantly different?
5.2.1 Block estimation of moments
To estimate the differences between estimators, we can first look at simple examples of independent realisations in which we sample a number of zeroes that corresponds to what is realistic for the proportion dry p at the scale of interest and a simple distribution for the rainfall depths of non-zero rainfalls is assumed, e.g. a gamma or generalised Pareto (hereafter GP) distribution (see Menabde and Sivapalan, 2000; Montfort and Witter, 1986), assuming Ny=50 and (for hourly data).
We found the differences to be less than 1 % in the case of either the variances or third-order moments as the additive terms in the equations relating them were found to be very small, for all the relevant timescales of interest (5 min to 24 h). In the case of the variance, this can be seen by noting that has a population variance that is that of the rainfall depths divided by Nm,h. So the sample variance is of the same order of magnitude as , which means that the added term in Eq. (10) will be very small. Similar considerations apply to the added terms in Eq. (11).
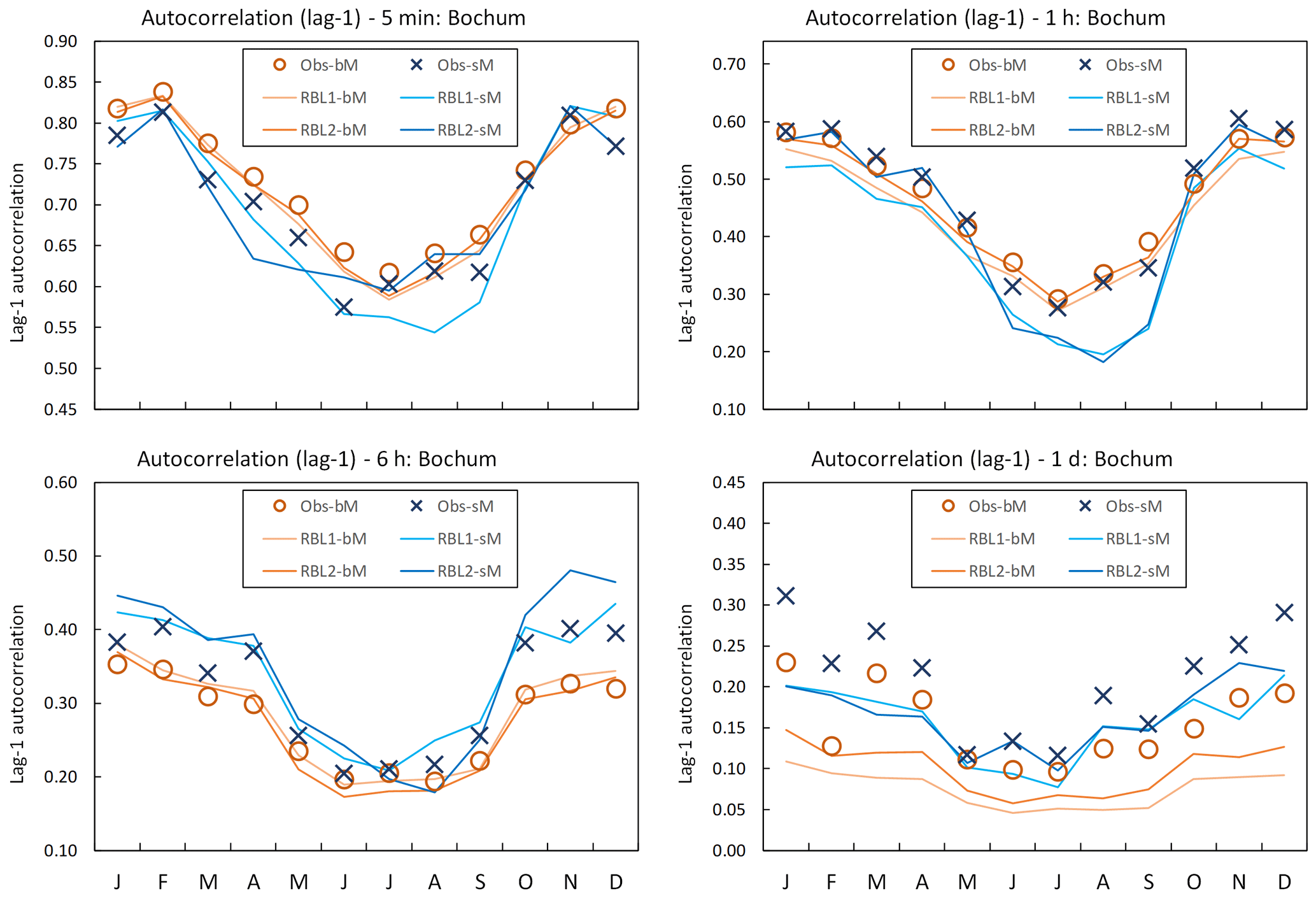
Figure 5Lag-1 autocorrelation by month at Bochum: the observed lag-1 autocorrelation calculated with block (Obs-bM, orange circle markers) vs. standard (Obs-sM, blue cross markers) methods, the same with the RBL1 (RBL1-bM, light orange line; RBL1-sM, light blue line) models and the same with the RBL2 (RBL2-bM, orange lines; RBL2-sM, blue lines) models.
We also checked that these two methods provide an unbiased estimation of the population second- and third-order centred moments, i.e. V=Var(X) and . These are easily obtained in terms of the corresponding moments (V>0 and M3>0) of the distribution of non-zero rainfalls (i.e. of a gamma or GP distribution) using the following easily derivable relations (where M and M>0 are the means of the full and the non-zero only distributions):
5.2.2 Block estimation of ratios
However, some authors apply the block estimation approach not to the moments themselves but to their ratios, i.e. the coefficient of variation instead of the variance and the coefficient of skewness instead of the third-order moment (e.g. Kaczmarska et al., 2014). That means that the block estimator of such ratios is obtained by averaging the estimates of these ratios from the relevant block from each of the years in the data set.
Here, there are no interesting relations to derive between the estimators from the standard and block methods, so we move directly to the simple numerical testing introduced in Sect. 5.2. For h=1 and a proportion of dry periods of 0.9, we fitted a gamma and a GP distribution to the non-zero rainfalls at Greenwich (UK). This yielded a Gamma(1.1629,0.692) distribution and a (GP distribution), respectively (with the first providing a better fit), with the parameters given, in order as shape, scale and, for the GP, location.
By generating 100 samples of 50 years of hourly data, we find that there is a non-negligible difference between the two estimation methods. Focusing upon the skewnesses, we find 95 % simulation bands of [5.68,6.65] and [5.50,6.15] for the gamma samples, i.e. differences that are still small but no longer negligible (of the order of 4 %). The block estimates clearly underestimate the population skewness of 6.40. Further, if we look at rainfall from a summer month, e.g. the month of August, these differences are more marked. For the gamma distribution (Gamma(0.848,1.4)) the bands are now [6.48,7.62] and [6.26,6.92], respectively, a difference that is twice as large for the upper bounds. Again, the population skewness of 7.05 is underestimated by the block method.
When using the GP distribution (), the differences between the two methods and the underestimation are starker. The bands are [7.94,13.97] and [7.21,8.55] for the standard and block method, respectively. The latter underestimates the population skewness of 10.58 by quite a margin (these results are for the whole year; for August, the GP fit was poor and the population skewness infinite).
These results now need to be confirmed by looking at the case of a time series with an appropriate correlation structure. This will enable us to ascertain to what extent introducing correlation impacts the performance of the estimators (which are, of course, theoretically designed for samples of independent realisations).
To do this, we use an RBL2 model calibrated to the same data used for the above sampling, namely Greenwich, UK. The idea is that this rainfall model provides us with a correlation structure that is close enough to the observed correlation to enable us to conclude as to how one would expect the block estimates to perform with such a correlation structure. We generate 100 samples of 50 years of hourly data with two sets of parameters, obtained from January (winter) and August (summer), respectively. The associated theoretical skewnesses calculated from these two parameter sets are 7.69 and 21.73. The 95 % simulation bands obtained from the sampled hourly time series are [6.80,7.65] and [12.67,14.65] using the block method and [7.11,8.44] and [16.70,28.40] using the standard method. In line with the numerical investigation above, we find that, for both months, the theoretical skewnesses provided by the model equation are underestimated by the block estimate (the underestimation is particularly significant during summer months), while no significant deviation is obtained for the standard estimates.
The results we have obtained are indicative of a problem of underestimation of the skewness with the block estimation method, which is likely to have a significant impact upon the model's ability to reproduce the statistics of extreme rainfall.
6.1 Block vs. standard estimates
Models RBL1 and RBL2 are fitted using the original equations for these models. Although these equations are not shown in this paper, they are contained in the new sets of equations given above: for each statistic, the first equation given is that found in the past papers, with its domain of validity for α. We note that, for RBL2, this is α>1 for all statistics, but we imposed α>2 for this model, in line with the work carried out by Kaczmarska et al. (2014). By using statistical estimators of the observed statistics based upon the standard and the block estimates as described in Sect. 5 (i.e. the block method takes the averages of ratios), we define two different fitting methods, the standard (sM) and block (bM) fitting methods, respectively.
Below, we consider the following:
-
some standard theoretical statistics obtained when the two models are fitted with both methods and how these compare with the estimates derived from the observations using the standard and block methods
-
the extreme rainfall depths produced by simulating time series of identical lengths to the observations, with 250 simulations being carried out and the median shown because of sampling variability
-
the values of the parameters obtained in fitting these models with these two methods.
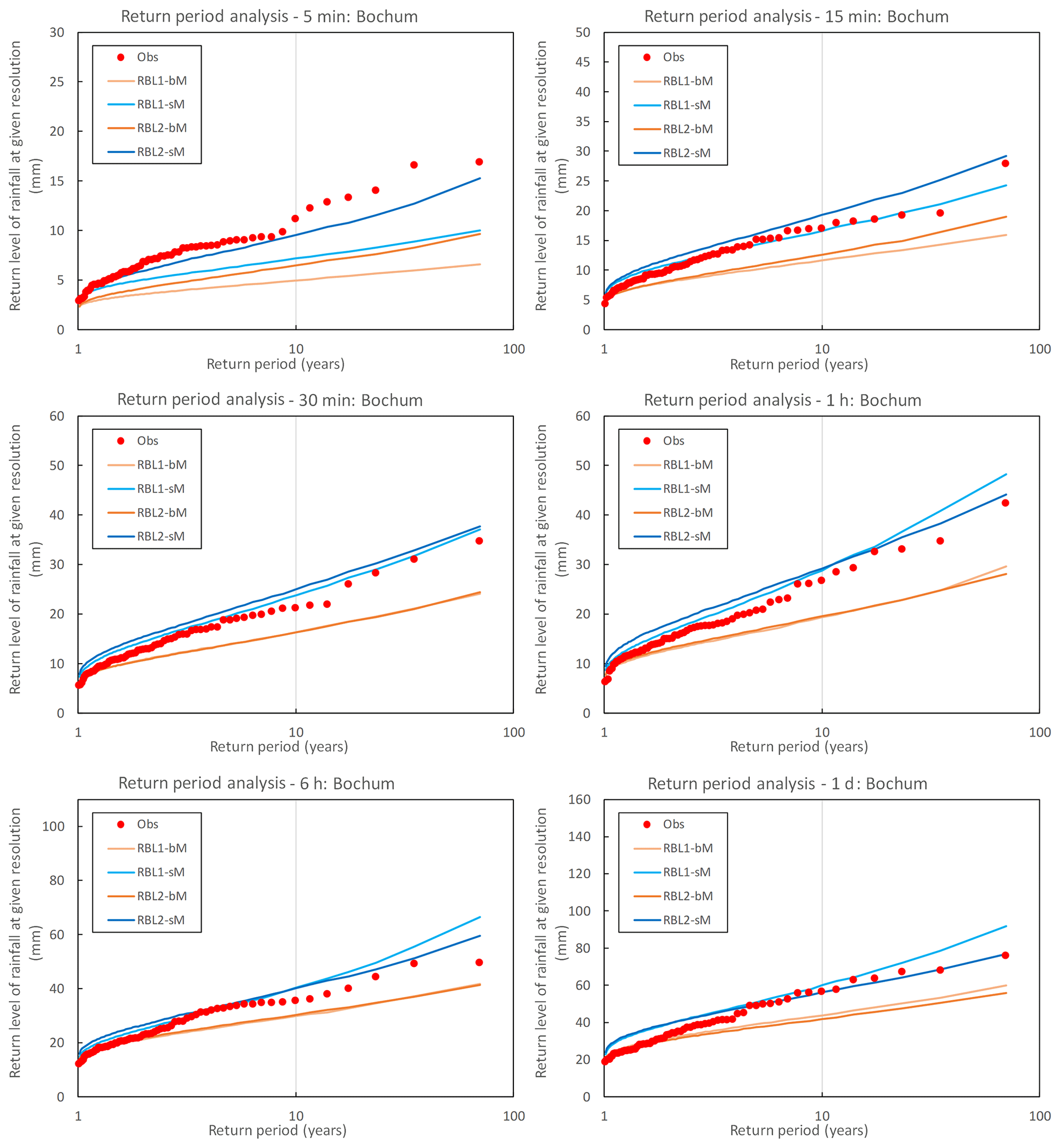
Figure 6Observed (round markers) and simulated (lines) return levels of rainfall at different timescales at Bochum. The simulated return level is sampled from the RBL1 and RBL2 models fitted with selected statistical properties calculated using bM and sM methods, respectively. The median return levels obtained from 250 simulations, each of 69 years, are illustrated.
While the mean rainfall depth (which has identical standard and block estimators) is nearly perfectly reproduced by both methods and models, Fig. 3 shows the differences in the skewness standard and block estimators (crosses and circles, respectively).
Consequently, the models fitted to each also yield significantly different skewnesses. Since we know from the preliminary investigation in Sect. 5 that the standard estimator is much less biased, this means that the block fitting method significantly underestimates the skewness of the observations. This is an important conclusion with respect to the validity of previous work which has used the block fitting method.
We also note some interesting features of the two models' performance:
-
Good fits are obtained for RBL1 and RBL2 with sM for all but the sub-hourly timescales.
-
At the finest timescale under consideration (i.e. 5 and 10 min for Bochum and Uccle, respectively), there is a considerable underestimation of the skewness for bM and sM, in particular by the RBL1 model. This confirms the superiority of RBL2 for fine timescales noted by Kaczmarska et al. (2014).
While these results confirm the importance of using the standard estimation of observation statistics, this message is not as clear when we consider the reproduction of the coefficient of variation and lag-1 autocorrelation, as Figs. 4 and 5 show.
Due to space constraints, the examination of the effect of changing between bM and sM upon the variances at coarser timescales will be presented together with the effect of using the new equations in Sect. 6.3.
From the figures above, we note the following:
-
The sub-hourly coefficients of variation estimated with the standard method are poorly reproduced by sM as compared with bM.
-
The same is true of the sub-hourly and hourly autocorrelations.
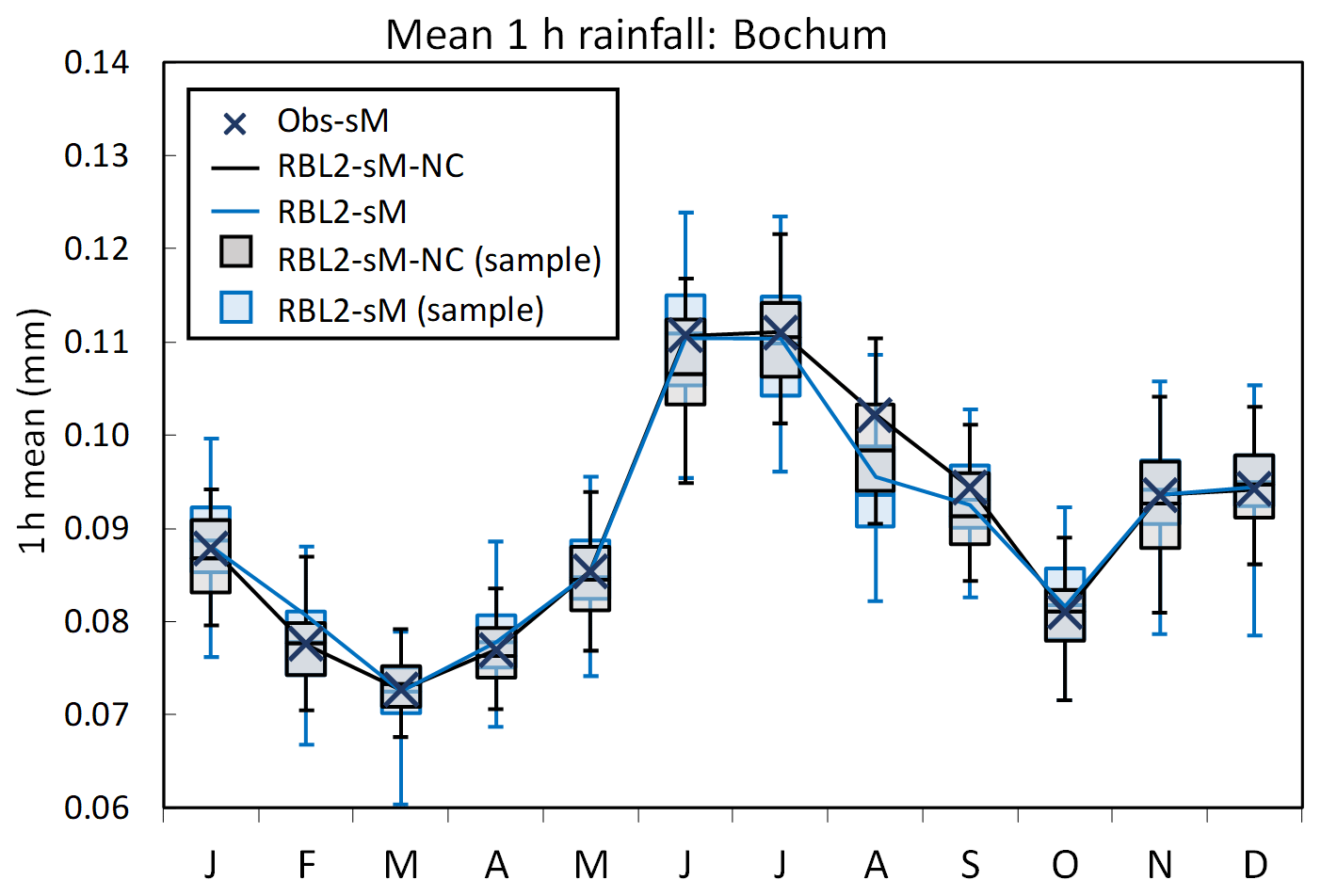
Figure 7Mean 1 h rainfall depths by month at Bochum: the observed vs. the fitted rainfall depths using the RBL2 models with the original and the new solution spaces of α (RBL1-sM, light blue lines and boxplots; RBL2-sM-NC, black lines and boxplots).

Figure 8Coefficient of variation (CV) by month at Bochum: the observed vs. the fitted CV using the RBL2 models with the original and the new solution spaces of α (RBL2-sM, light blue lines and boxplots; RBL2-sM-NC, black lines and boxplots).
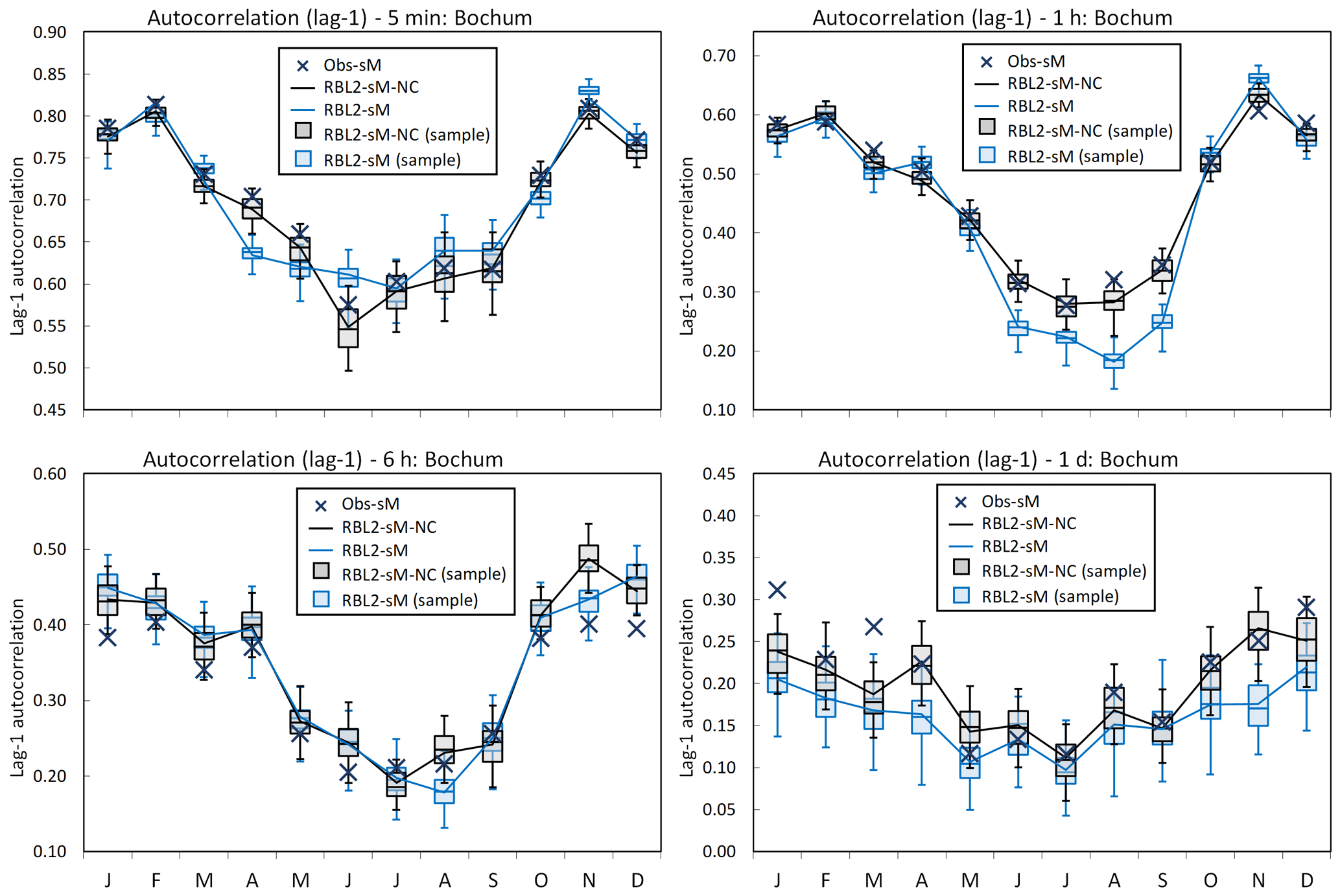
Figure 9Lag-1 autocorrelation by month at Bochum: the observed vs. the fitted lag-1 autocorrelation using the RBL2 models with the original and the new solution spaces of α (RBL2-sM, light blue lines and boxplots; RBL2-sM-NC, black lines and boxplots).
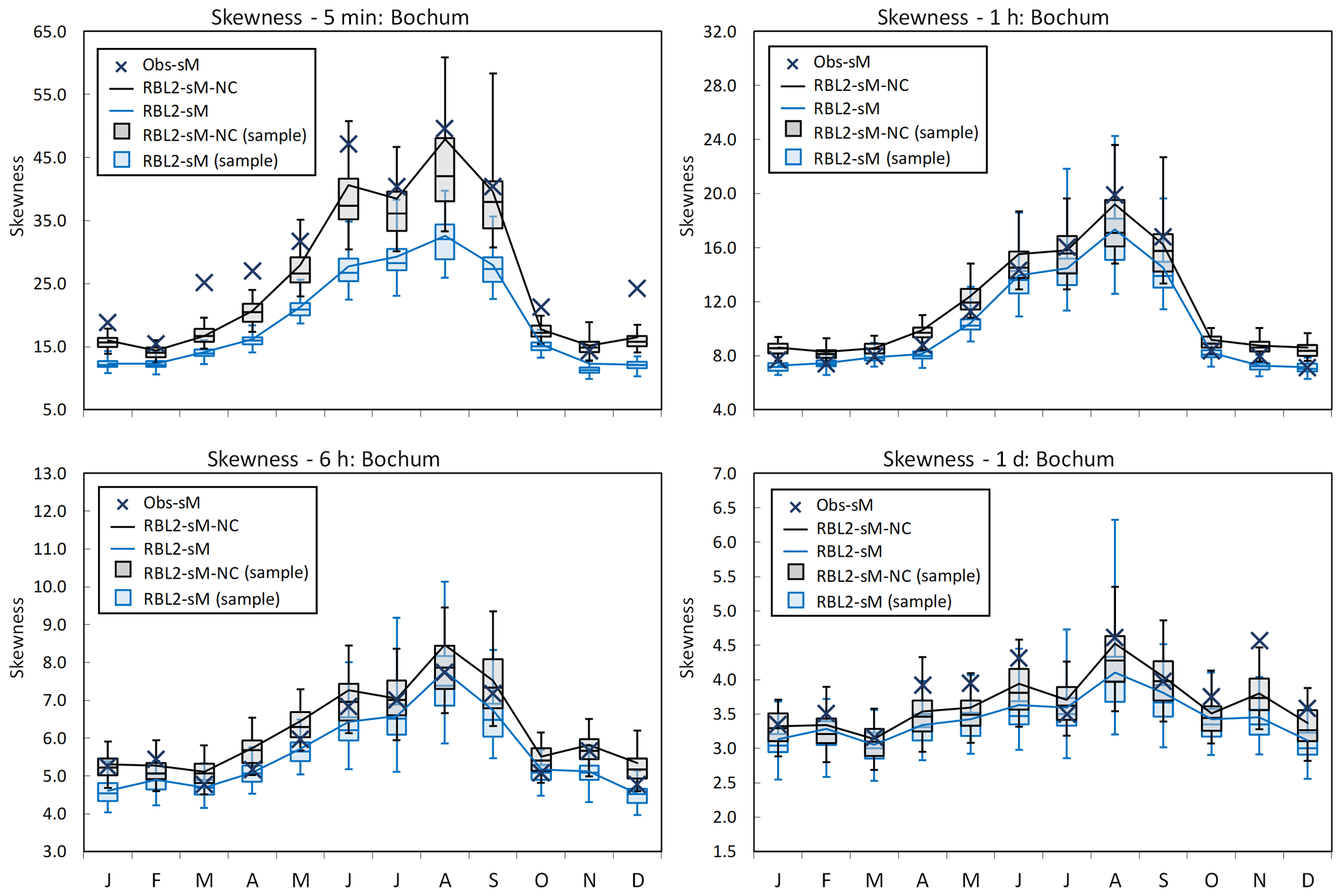
Figure 10Coefficient of skewness by month at Bochum: the observed vs. the fitted coefficient of skewness using the RBL2 models with the original and the new solution spaces of α (RBL2-sM, light blue lines and boxplots; RBL2-sM-NC, black lines and boxplots).
These results might seem a little surprising, so it is important to spell out exactly what they mean: the models fitted to the block estimates provide in some cases a better reproduction of the statistics than the models fitted to the standard estimates. This at the very least suggests that the improved reproduction of the skewness by sM comes at the cost of other statistics being less well reproduced.
The benefit of an improved reproduction of the skewness upon the models' ability to reproduce the frequency of rainfall extremes at a range of scales is clear, as Fig. 6 shows.
Here, we observe the following:
-
sM significantly improves the reproduction of the extremes.
-
RBL2 is superior to RBL1, in terms of reproducing the largest extremes in particular at the sub-hourly scales but also, for instance, at the daily scale.
The importance of the reproduction of extreme values for the typical applications of such rainfall models means that even taking into account the problems with the mean, coefficient of variation and autocorrelation, sM is preferred. But this leaves us with an important question: are the shortcomings of sM in reproducing some of these other statistics down to the model or the way it is fitted?
A clue to addressing this question can be obtained by looking at the parameters obtained when fitting with the sM method. Focusing for instance upon RBL2 and recalling the constraint α>2, Table 1 shows that the model calibration has yielded values of α on the boundary (as in Kaczmarska et al., 2014).
Table 1Parameters for the RBL2-sM model using Bochum gauge data; constraint: α>2.
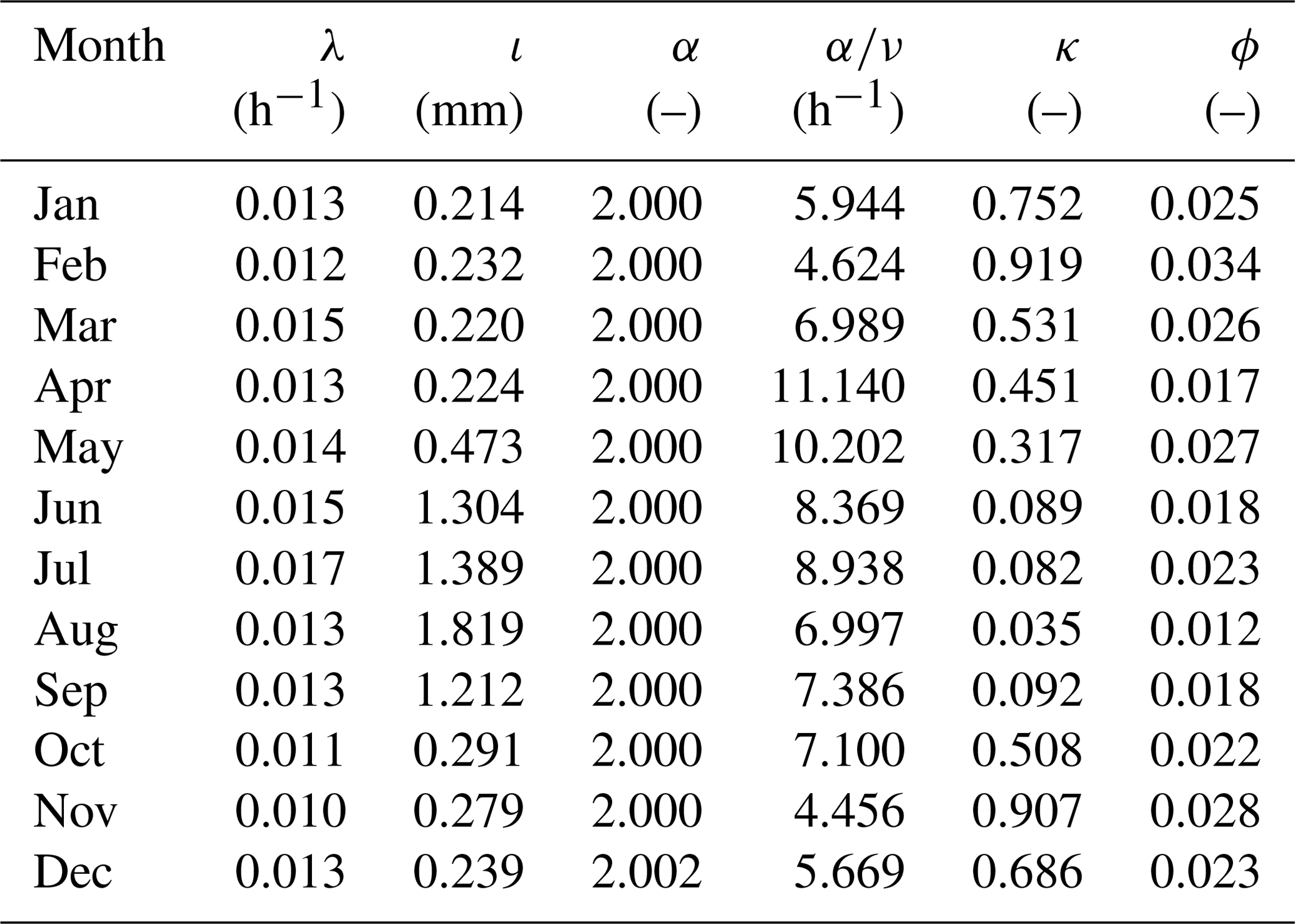
Recalling that α is the shape parameter of the distribution of η, a smaller α leads to a more skewed distribution for this parameter and thereby also for those which scale with it, such as the storm mean cell intensity in the case of RBL2. This enables RBL2 to generate some much more intense cells and thereby yields higher values of the skewness of rainfall depths as we saw above, thereby explaining its superiority over RBL1.
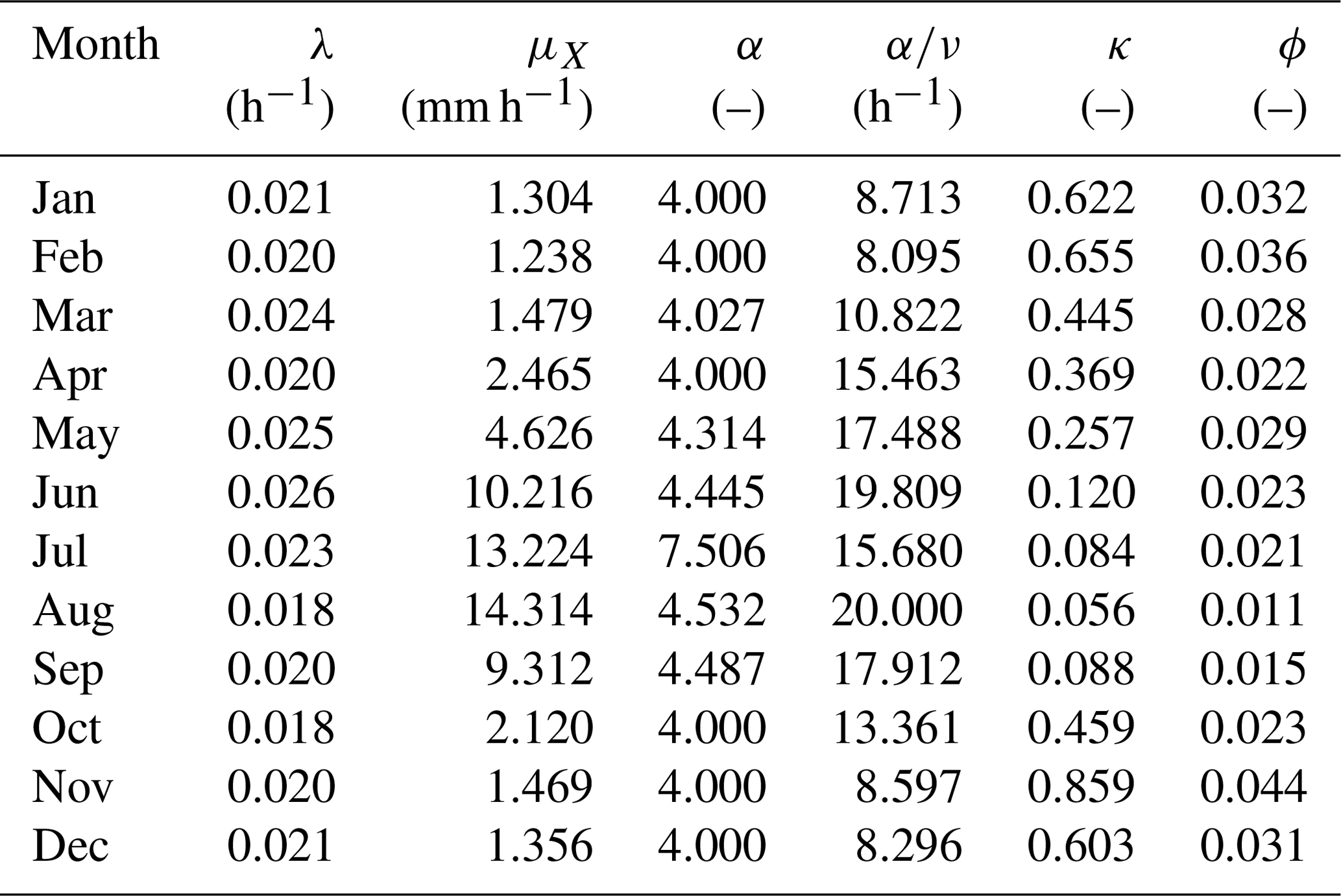
For model RBL1, the constraint upon α is defined by the limit of validity of the expression for the skewness (e.g. Onof et al., 2013), i.e. α>4. The parameters that are obtained (Table 2) similarly show that the optimisation algorithm finds the optimum to be near this boundary for most months of the year.
Table 2Parameters for the RBL1-sM model using Bochum gauge data; constraint: α>4.
For both models, the fact that the lower limit of parameter α is selected as optimal suggests that a re-examination of the domain of feasibility of the non-linear optimisation carried out when fitting the models is required. This is exactly what the use of the new equations allows us to do as we shall see below. Note that all the above results are confirmed by the Uccle data (see Sect. S4 in the Supplement).
6.2 New vs. old equations
We now consider the performance of models RBL1 and RBL2 fitted using the new equations for these models presented in this paper. The impact of the use of these equations, if there is any, will be that of an extension of the domain of feasibility of parameter α. Since the results presented above have concluded the superiority of the standard estimates of observation statistics, we shall use this method in what follows. As in the previous section, we examine (i) model parameters, (ii) the reproduction of standard statistics and (iii) the reproduction of the statistics of extreme rainfall depth.
Here it is useful to start with the parameters shown in Tables 3 and 4.
Table 3Parameters for the RBL1-sM-NC model using Bochum gauge data; constraint: α>2.

Table 4Parameters for the RBL2-sM-NC model using Bochum gauge data; constraint: α>0.
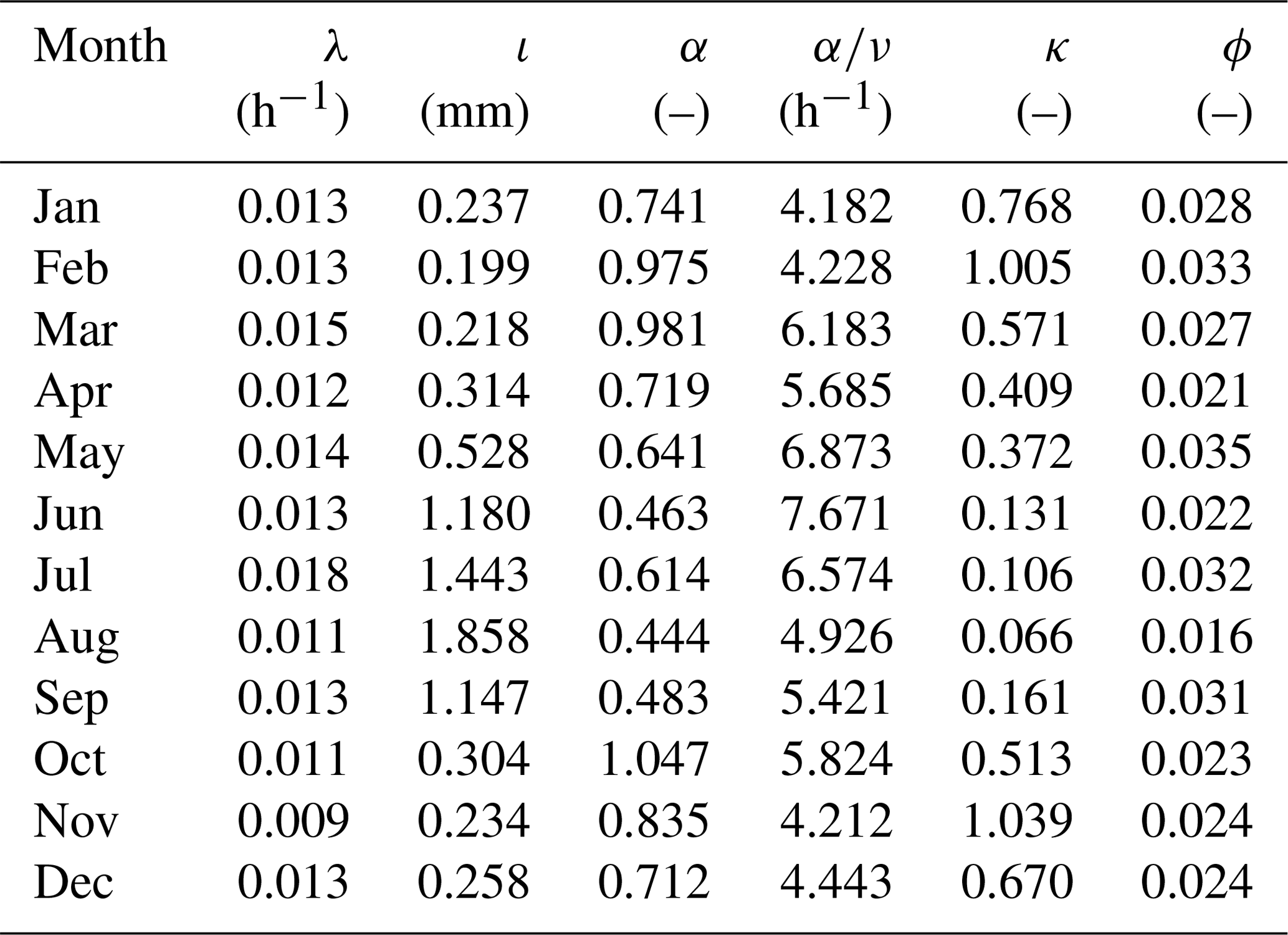
We see that for most months in the case of RBL1 and for all but a single month in the case of RBL2, the optimal value of α was found outside the domain of feasibility imposed by the equations used in previous research, i.e. α>4 for RBL1 and α>1 for RBL2. For RBL1, we can check that for the months where the new values of α remain inside the old domain of feasibility, the optimal values of α are very similar to those in Table 2. The fact that they are not identical is down to the randomness in the numerical tool used to optimise the objective function.
Table 5Comparison minimum objective function values for different RBL models using Bochum gauge data.
Looking now at the standard statistics, Figs. 7–10 illustrate the impact of relaxing the constraint upon α in terms of the reproduction of the mean, coefficient of variation, lag-1 autocorrelation and skewness of the rainfall depths.
In these figures, aside from the theoretical estimates of the statistics, we show box plots of their sample estimates based upon 250 simulations of 5 min (and 10 min for Uccle; see Sect. S4 in Supplement) time series of length equal to that of the observations (69 and 105 years for Bochum and Uccle, respectively). This is for two reasons. First it is important to check that the equations derived above are correct, which we can do by comparing estimates from these simulations with the theoretical values. Second, by including information about the simulation bands, we show the sampling variability which is useful to judge by how much a model statistic over- or underestimates the corresponding observation statistic.
What the figures show very clearly is a general improvement of the reproduction of all these statistics through the use of new equations. The broadening of parameter space thus enables the model to overcome the problem flagged earlier, namely that the attempt to reproduce fine-scale skewnesses led to a deterioration in the reproduction of the other depth statistics.
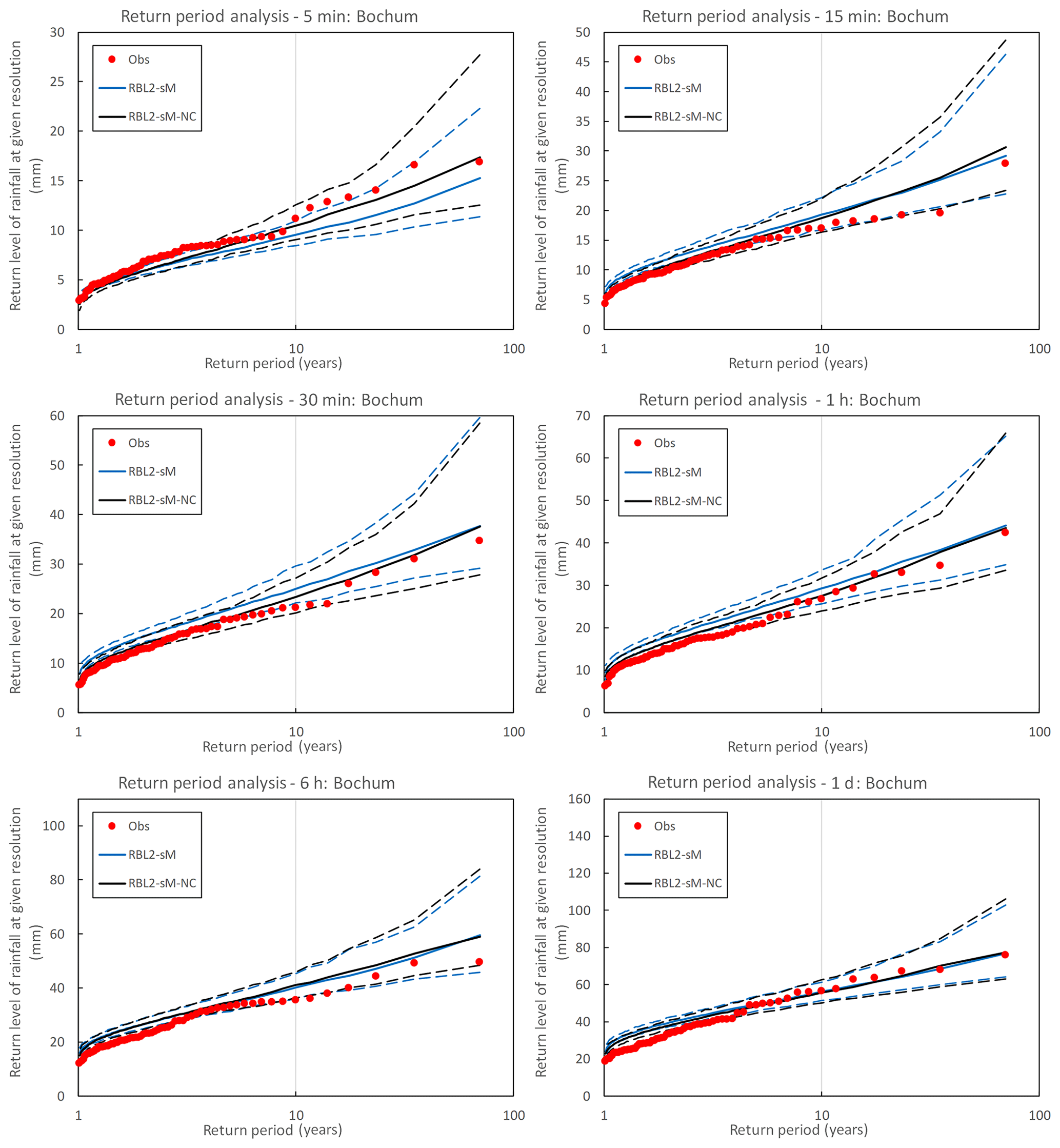
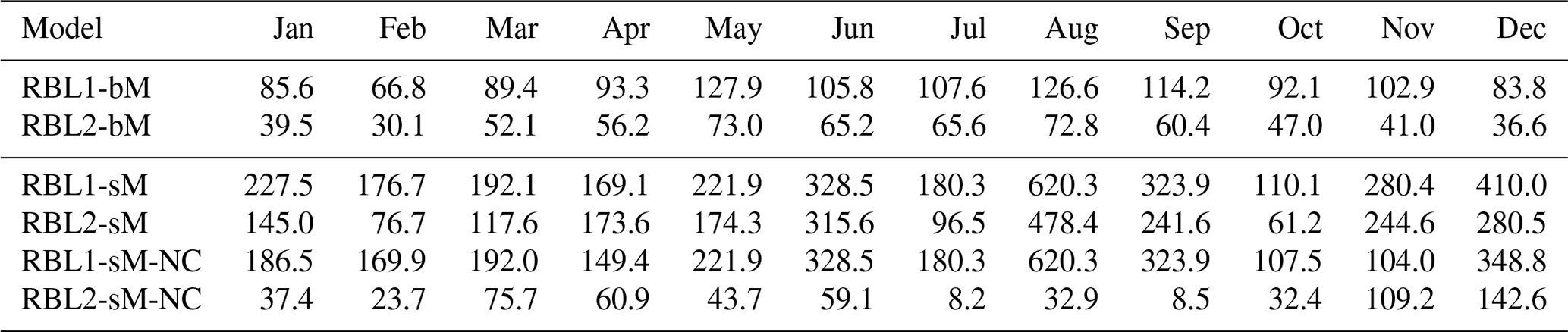
Figure 11Observed (round markers) and simulated (lines) return levels of rainfall at multiple timescales at Bochum. The simulated return level is sampled from the RBL2 models fitted with the original (blue lines) and the new (black lines) solution spaces of α. The median, 95th and 5th percentile return levels obtained from 250 simulations, each of 69 years, are plotted with solid and dashed lines, respectively.
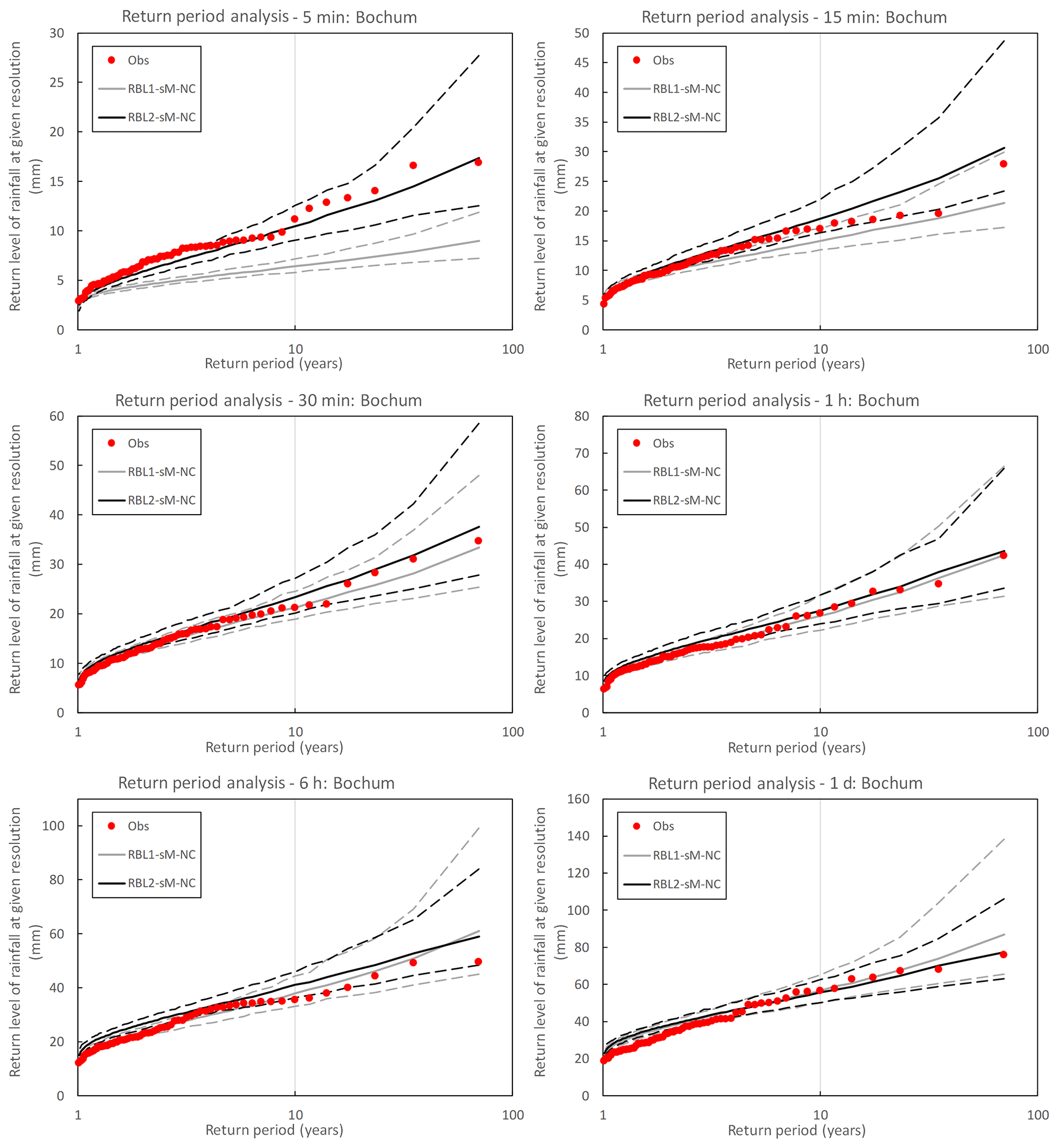
Figure 12Observed (round markers) and simulated (lines) return levels of rainfall at multiple timescales at Bochum. The simulated return level is sampled from the RBL1 (grey lines) and RBL2 (black lines) models fitted with the new solution spaces of α. The median, 95th and 5th percentile return levels obtained from 250 simulations, each of 69 years, are plotted with solid and dashed lines, respectively.
Figure 13Daily variances by month at Bochum: the observed daily variances calculated with standard (Obs-sM, blue cross markers) methods, those fitted with the RBL1 (RBL1-bM, light orange line; RBL1-sM, light blue line; RBL1-sM-NC, grey line) models and those fitted with the RBL2 (RBL2-bM, orange lines; RBL2-sM, blue lines; RBL2-sM-NC, black line) models.
In particular, we want to draw the reader's attention to RBL2's ability to reproduce the skewness at all scales of interest. This bodes well for its extreme value performance which is shown in Fig. 11.
The improvement brought about by the broader parameter space is particularly clear at the finest scale of interest (i.e. 5 and 10 min for Bochum and Uccle, respectively). But we also note an improved reproduction of the extremes of lower return periods for the sub-hourly and hourly timescales. These are however rather overestimated by both versions of the RBL2 model for coarser timescales.
Without looking into the detail of the RBL1 model, the question of its performance as compared to RBL2, with the new sets of equations in both cases, is illustrated in Fig. 12.
While noting that the above findings are broadly confirmed by the analysis of the Uccle data (see Sect. S4 in Supplement), we can conclude that RBL2 outperforms RBL1 for sub-hourly and hourly timescales (the 20 min results at Uccle excepted). Aside from a somewhat better reproduction of low return period extremes by RBL1 at the 6-hourly scale for Bochum, and since both models provide an equivalent satisfactory reproduction of the daily extreme rainfall depths (RBL2 is better for Uccle), RBL2 is therefore overall to be preferred for the reproduction of observed extremes.
6.3 Reproduction of coarse-scale variances
We briefly look at the impacts of the change of the estimator of observational statistics and the use of the new equations upon the reproduction of coarse-scale variability.
Figure 13 shows the following:
-
As expected, the sM parameter estimates clearly outperform the bM estimates.
-
Unlike at finer timescales, there is no clear improvement of the reproduction of the variance for scales longer than 1 d using new equations.
-
Beyond 7 d, many, and particularly the largest, of the variances are underestimated in line with the observations made by Marani (2003). This is even clearer in the case of the Uccle data (see Fig. S11 in Supplement).
This suggests that the issue of large-scale variability is probably best addressed by combining Poisson cluster models with a coarse-scale model that constrain them so that large-scale variances are reproduced.
This paper has both corroborated certain observations made in previous studies and identified two important issues about how randomised Bartlett–Lewis models are fitted. The work presented in this paper can be summarised in the following five points. First, the importance of the inclusion of the coefficient of skewness among the fitting properties (Cowpertwait, 1998) has indirectly been confirmed: it plays a key role in enabling a good reproduction of rainfall extremes. Second, the new randomised model (RBL2) introduced by Kaczmarska et al. (2014) has an overall better performance than the earlier version originally presented by Rodriguez-Iturbe et al. (1988), in particular in terms of its ability to reproduce extreme values and at hourly and sub-hourly timescales. Third, we have shown that, while the weights used in the objective function require that estimates of the statistical properties used in the fitting to be derived for each single month of the data set (to obtain their variance), in particular in the case of ratios such as the coefficients of variation or of skewness, these estimates should not be used to derive the overall estimates of the relevant statistical property. Rather, the estimates of rainfall statistics for each calendar month are best derived by pooling together all data from the relevant calendar month (with due attention to the separation between years in the case of the autocovariance) and using the standard sample statistics. Fourth, we have shown that the parameter spaces assumed in previous studies could be extended by relaxing the constraints imposed upon a parameter common to both randomised models (α). This improves in particular the RBL2 model's performance in reproducing both standard and extreme value statistics at sub-hourly and hourly timescales. Fifth, the reproduction of coarse-scale variances (of a few days and more) is improved by using the standard method of estimating observation statistics, but the broader parameter space does not add much. As a result, we find that these Bartlett–Lewis models still tend rather to underestimate the variability at scales coarser than a week, which provides a confirmation of the wisdom of developing combinations of Bartlett–Lewis models with simple coarse-scale models to capture long-term variability (e.g. see Park et al., 2019, and Kim and Onof, 2020).
The complete formulae are given here for the selected statistical moments based upon different parameter ranges. These include mean, variance, lag-k autocovariance and the third central moment of the discrete time aggregated process of the OBL, RBL1 and RBL2 models.
The definitions of the model parameters used are given below, with parameters that are only valid in some of the models indicated in square brackets:
-
h: timescale
-
λ: storm arrival rate
-
η: cell duration parameter [OBL]
-
α: shape parameter for the gamma distribution of the cell duration parameter (η) [RBL1, RBL2]
-
ν: scale parameter for the gamma distribution of η [RBL1, RBL2]
-
β: cell arrival rate [OBL]
-
κ: ratio of the cell arrival rate to η (i.e. β∕η)
-
γ: storm termination rate [OBL]
-
ϕ: ratio of the storm termination rate to η (i.e. γ∕η)
-
μX=E[X]: mean cell intensity [OBL, RBL1]
-
: mean of squares of cell intensities [OBL, RBL1]
-
: mean of cubes of cell intensities [OBL, RBL1]
-
ι: ratio of mean cell intensity to η (i.e. μX∕η) [RBL2]
-
-
-
: mean number of cells per storm.
A1 Bartlett–Lewis Rectangular Pulse model (OBL)
The mean is
The variance is
The covariance at lag k≥1 is
The third central moment is
where the quantities are given by the following equations:
A2 Randomised Bartlett–Lewis Rectangular Pulse model (RBL1)
The mean is
The variance is
The covariance at lag k≥1 is
The third central moment is
and the quantities are given by the following equations:
A3 Randomised Bartlett–Lewis Rectangular Pulse model with dependent intensity duration (RBL2)
The mean is
The variance is
The covariance at lag k≥1 is
The third central moment is
with
The rain gauge data used in this research are not publicly accessible. These data belong to Deutsche Montan Technologie, the Emschergenossenschaft and Lippeverband, and the Royal Meteorological Institute of Belgium, respectively. They were accessed via personal contact for this research.
The supplement related to this article is available online at: https://doi.org/10.5194/hess-24-2791-2020-supplement.
CO and LPW conceptualised the research idea and designed the experiment. CO derived new equations. LPW validated the equations and implemented code and performed the simulations. CO prepared the paper with contributions from LPW.
The authors declare that they have no conflict of interest.
This research is part of FloodCitiSense project, funded by the JPI for Urban Europe ERA-NET co-fund Smart Urban Futures (ENSUF) programme. The authors would also like to thank Deutsche Montan Technologie and the Emschergenossenschaft and Lippeverband for providing Bochum rainfall data and the Royal Meteorological Institute of Belgium for providing Uccle rainfall data.
This research has been supported by the European Union's Horizon 2020 research and innovation programme (grant no. 693443).
This paper was edited by Nadav Peleg and reviewed by Dongkyun Kim and two anonymous referees.
Arnbjerg-Nielsen, K.: Quantification of climate change effects on extreme precipitation used for high resolution hydrologic design, Urban Water J., 9, 57–65, https://doi.org/10.1080/1573062X.2011.630091, 2012. a, b
Arnbjerg-Nielsen, K., Willems, P., Olsson, J., Beecham, S., Pathirana, A., Bülow Gregersen, I., Madsen, H., and Nguyen, V.-T.-V.: Impacts of climate change on rainfall extremes and urban drainage systems: a review, Water Sci. Technol., 68, 16–28, https://doi.org/10.2166/wst.2013.251, 2013. a
Burlando, P. and Rosso, R.: Stochastic Models of Temporal Rainfall: Reproducibility, Estimation and Prediction of Extreme Events, in: Stochastic Hydrology and its Use in Water Resources Systems Simulation and Optimization, edited by: Marco, J. B., Harboe, R., and Salas, J. D., Springer Netherlands, Dordrecht, the Netherlands, 137–173, https://doi.org/10.1007/978-94-011-1697-8_7, 1993. a
Connolly, R., Schirmer, J., and Dunn, P.: A daily rainfall disaggregation model, Agr. Forest Meteorol., 92, 105–117, https://doi.org/10.1016/S0168-1923(98)00088-4, 1998. a
Cowpertwait, P. S. P.: A Poisson-cluster model of rainfall: some high-order moments and extreme values, P. Roy. Soc. Lond. A Mat., 454, 885–898, https://doi.org/10.1098/rspa.1998.0191, 1998. a, b, c
Cross, D., Onof, C., and Winter, H.: Ensemble simulation of future rainfall extremes with temperature dependent censored simulation, Adv. Water Resour., 136, 103479, https://doi.org/10.1016/j.advwatres.2019.103479, 2020. a
Efstratiadis, A., Koutsoyiannis, D., and Polytechniou, H.: An evolutionary annealing-simplex algorithm for global optimisation of water resource systems, Proceedings of the Fifth International Conference on Hydroinformatics, 1–5 July 2002, Cardiff, UK, International Water Association, https://doi.org/10.13140/RG.2.1.1038.6162, 2002. a
Evin, G. and Favre, A.-C.: A new rainfall model based on the Neyman-Scott process using cubic copulas, Water Resour. Res., 44, W03433, https://doi.org/10.1029/2007WR006054, 2008. a
Jesus, J. and Chandler, R. E.: Estimating functions and the generalized method of moments, Interface Focus, 1, 871–885, https://doi.org/10.1098/rsfs.2011.0057, 2011. a
Kaczmarska, J., Isham, V., and Onof, C.: Point process models for fine-resolution rainfall, Hydrolog. Sci. J., 59, 1972–1991, https://doi.org/10.1080/02626667.2014.925558, 2014. a, b, c, d, e, f, g, h, i, j, k, l, m, n
Kaczmarska, J. M., Isham, V. S., and Northrop, P.: Local generalised method of moments: an application to point process-based rainfall models, Environmetrics, 26, 312–325, https://doi.org/10.1002/env.2338, 2015. a
Khaliq, M. and Cunnane, C.: Modelling point rainfall occurrences with the modified Bartlett-Lewis rectangular pulses model, J. Hydrol., 180, 109–138, https://doi.org/10.1016/0022-1694(95)02894-3, 1996. a, b
Kim, D. and Onof, C.: A stochastic rainfall model that can reproduce important rainfall properties across the timescales from several minutes to a decade, J. Hydrol., in review, 2020. a
Kim, J.-G., Kwon, H.-H., and Kim, D.: A hierarchical Bayesian approach to the modified Bartlett-Lewis rectangular pulse model for a joint estimation of model parameters across stations, J. Hydrol., 544, 210–223, https://doi.org/10.1016/j.jhydrol.2016.11.031, 2017. a
Kossieris, P., Makropoulos, C., Onof, C., and Koutsoyiannis, D.: A rainfall disaggregation scheme for sub-hourly time scales: Coupling a Bartlett-Lewis based model with adjusting procedures, J. Hydrol., 556, 980–992, https://doi.org/10.1016/j.jhydrol.2016.07.015, 2018. a
Koutsoyiannis, D. and Mamassis, N.: On the representation of hyetograph characteristics by stochastic rainfall models, J. Hydrol., 251, 65–87, https://doi.org/10.1016/S0022-1694(01)00441-3, 2001. a
Marani, M.: On the correlation structure of continuous and discrete point rainfall, Water Resour. Res., 39, 1128, https://doi.org/10.1029/2002WR001456, 2003. a, b
Menabde, M. and Sivapalan, M.: Modeling of rainfall time series and extremes using bounded random cascades and levy-stable distributions, Water Resour. Res., 36, 3293–3300, https://doi.org/10.1029/2000WR900197, 2000. a
Montfort, M. A. and Witter, J. V.: The Generalized Pareto distribution applied to rainfall depths, Hydrolog. Sci. J., 31, 151–162, https://doi.org/10.1080/02626668609491037, 1986. a
Onof, C. and Arnbjerg-Nielsen, K.: Quantification of anticipated future changes in high resolution design rainfall for urban areas, Atmos. Res., 92, 350–363, https://doi.org/10.1016/j.atmosres.2009.01.014, 2009. a, b
Onof, C. and Wheater, H. S.: Modelling of British rainfall using a random parameter Bartlett-Lewis Rectangular Pulse Model, J. Hydrol., 149, 67–95, https://doi.org/10.1016/0022-1694(93)90100-N, 1993. a, b, c
Onof, C. and Wheater, H. S.: Improvements to the modelling of British rainfall using a modified Random Parameter Bartlett-Lewis Rectangular Pulse Model, J. Hydrol., 157, 177–195, https://doi.org/10.1016/0022-1694(94)90104-X, 1994. a
Onof, C., Chandler, R. E., Kakou, A., Northrop, P., Wheater, H. S., and Isham, V.: Rainfall modelling using Poisson-cluster processes: a review of developments, Stoch. Env. Res. Risk A., 14, 384–411, https://doi.org/10.1007/s004770000043, 2000. a, b, c
Onof, C., Meca-Figueras, T., Kaczmarska, J., Chandler, R., and Hege, L.: Modelling rainfall with a Bartlett–Lewis process: third order moments, proportion dry, and a truncated random parameter version, Tech. rep., Imperial College London, London, UK, 2013. a, b
Park, J., Onof, C., and Kim, D.: A hybrid stochastic rainfall model that reproduces some important rainfall characteristics at hourly to yearly timescales, Hydrol. Earth Syst. Sci., 23, 989–1014, https://doi.org/10.5194/hess-23-989-2019, 2019. a, b
Paschalis, A., Molnar, P., Fatichi, S., and Burlando, P.: On temporal stochastic modeling of precipitation, nesting models across scales, Adv. Water Resour., 63, 152–166, https://doi.org/10.1016/j.advwatres.2013.11.006, 2014. a
Ramesh, N. I.: Statistical analysis on Markov-modulated Poisson processes, Environmetrics, 6, 165–179, https://doi.org/10.1002/env.3170060207, 1995. a
Ramesh, N. I., Garthwaite, A. P., and Onof, C.: A doubly stochastic rainfall model with exponentially decaying pulses, Stoch. Env. Res. Risk A., 32, 1645–1664, https://doi.org/10.1007/s00477-017-1483-z, 2018. a
Rodriguez-Iturbe, I., Cox, D. R., and Isham, V.: Some models for rainfall based on stochastic point processes, P. Roy. Soc. Lond. A Mat., 410, 269–288, https://doi.org/10.1098/rspa.1987.0039, 1987. a, b, c, d
Rodriguez-Iturbe, I., Cox, D. R., and Isham, V.: A point process model for rainfall: further developments, P. Roy. Soc. Lond. A Mat., 417, 283–298, https://doi.org/10.1098/rspa.1988.0061, 1988. a, b, c, d, e, f
Verhoest, N., Troch, P. A., and Troch, F. P. D.: On the applicability of Bartlett–Lewis rectangular pulses models in the modeling of design storms at a point, J. Hydrol., 202, 108–120, https://doi.org/10.1016/S0022-1694(97)00060-7, 1997. a, b
Verhoest, N. E. C., Vandenberghe, S., Cabus, P., Onof, C., Meca-Figueras, T., and Jameleddine, S.: Are stochastic point rainfall models able to preserve extreme flood statistics?, Hydrol. Process., 24, 3439–3445, https://doi.org/10.1002/hyp.7867, 2010. a, b, c
Wang, L., Onof, C., and Maksimovic, C.: Reconstruction of sub-daily rainfall sequences using multinomial multiplicative cascades, Hydrol. Earth Syst. Sci. Discuss., 7, 5267–5297, https://doi.org/10.5194/hessd-7-5267-2010, 2010. a
Wheater, H. S., Isham, V. S., Chandler, R. E., Onof, C., Bellone, E., Prudhomme, C., and Crooks, S.: Improved methods for national spatial-temporal rainfall and evaporation modelling for BSM, Tech. rep., DEFRA, available at: http://randd.defra.gov.uk/Document.aspx?Document=FD2105_6227_PR.pdf (last access: 11 October 2019), 2006. a, b
- Abstract
- Background
- Data
- Model structure
- Model calibration and the revised equations
- Model calibration and the estimation of standard statistics
- Results and discussion
- Conclusions
- Appendix A: Formulae for fitting properties
- Data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
The requested paper has a corresponding corrigendum published. Please read the corrigendum first before downloading the article.
- Article
(5505 KB) - Full-text XML
- Corrigendum
-
Supplement
(1904 KB) - BibTeX
- EndNote
- Abstract
- Background
- Data
- Model structure
- Model calibration and the revised equations
- Model calibration and the estimation of standard statistics
- Results and discussion
- Conclusions
- Appendix A: Formulae for fitting properties
- Data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement